What Is Apache Flink?
Apache Flink is an open-source, distributed stream processing framework designed for high-throughput, low-latency processing of continuous data streams with exactly-once semantics and stateful computation. Originally developed at the Technical University of Berlin in 2010 and donated to the Apache Software Foundation in 2014, Flink has grown into the leading open-source stream processing engine, widely used at Alibaba, Netflix, Uber, LinkedIn, and many other large-scale data organizations.
Flink's core innovation over earlier streaming frameworks (like Apache Storm) is its unified stream-batch model: Flink processes all data as streams, with bounded (finite) streams representing batch workloads and unbounded (infinite) streams representing real-time workloads. This unification means the same Flink program and the same execution semantics apply to both batch and streaming data.
In the data lakehouse ecosystem, Flink's primary role is streaming ingestion — continuously reading from message queues (Apache Kafka, AWS Kinesis, Apache Pulsar) and CDC sources, applying real-time transformations, and writing to Apache Iceberg tables with exactly-once delivery guarantees. This enables lakehouse data freshness measured in seconds or minutes rather than hours.
Flink and Apache Iceberg
The Flink-Iceberg integration is one of the most production-proven streaming Iceberg write patterns. The key components:
Flink Iceberg Sink
The FlinkSink class writes DataStream or Table API results to Iceberg tables. It buffers incoming rows, commits batches to Iceberg as new snapshots aligned with Flink checkpoints, and provides exactly-once semantics through Flink's checkpoint mechanism — ensuring that even if the Flink job restarts, each row appears exactly once in the Iceberg table.
Append Mode
New rows are added to the Iceberg table as new data files on each checkpoint commit. Ideal for Bronze ingestion of event streams (logs, clickstreams, IoT telemetry) where each event is immutable and unique.
UPSERT Mode
Updates and deletes from CDC sources are applied to the Iceberg table using Iceberg V2 equality delete files. This enables real-time CDC ingestion directly into Silver Iceberg tables without a separate MERGE INTO batch step.
Flink CDC: Debezium to Iceberg
One of the most common production Flink patterns is the Debezium CDC to Iceberg pipeline:
- Debezium connector reads the MySQL/PostgreSQL WAL (write-ahead log) and publishes change events (INSERT, UPDATE, DELETE) to Kafka topics in Debezium JSON format
- Flink job reads the Kafka Debezium topics using the
flink-cdc-connectorslibrary, which parses Debezium events into Flink RowData with change type metadata - Transformation: Optional business logic applied in Flink (joining, enrichment, deduplication)
- Iceberg sink: Flink writes to the target Iceberg table in UPSERT mode — inserts become new data files, updates/deletes become equality delete files
This pattern delivers data from the source operational database into the Iceberg Silver table within 30–120 seconds of the source change — enabling near-real-time analytics without the complexity of maintaining a custom streaming ETL pipeline.
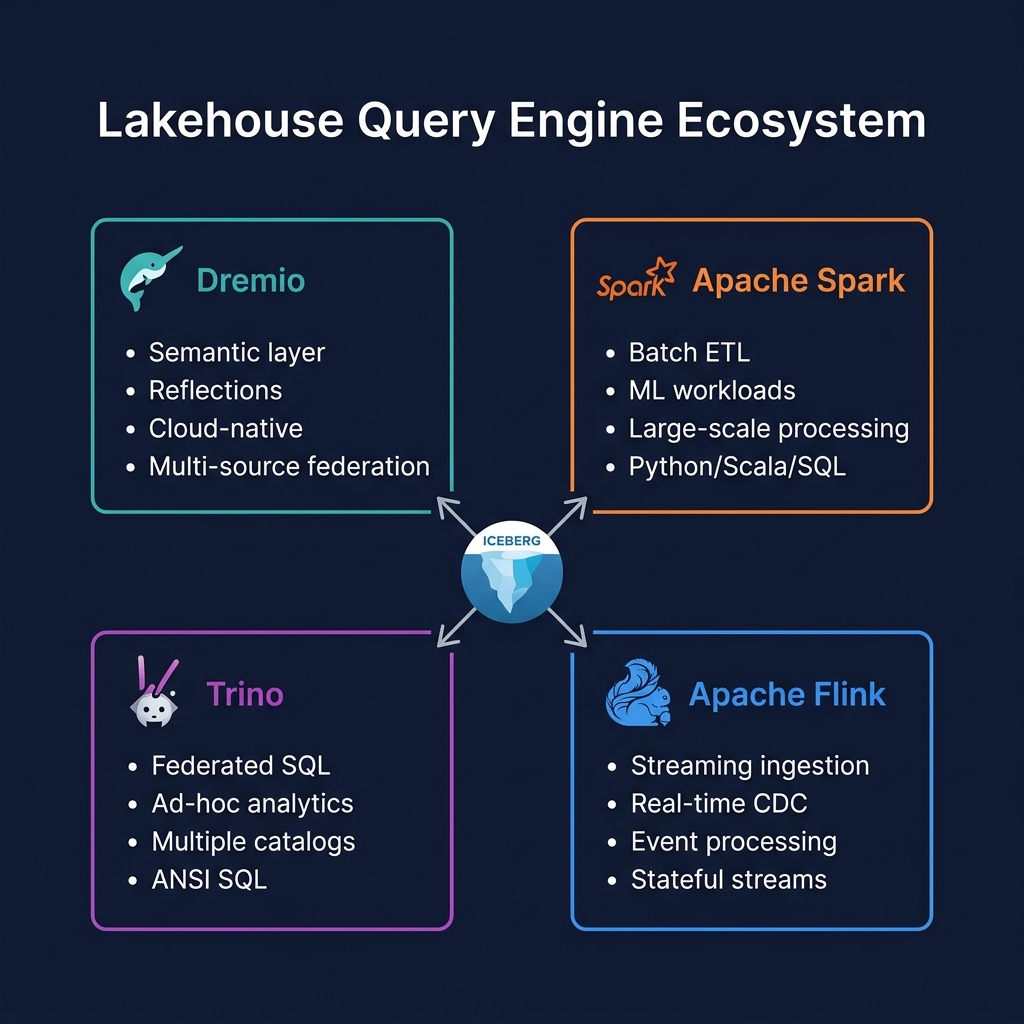
Flink vs. Spark Structured Streaming
Both Flink and Spark Structured Streaming can ingest data into Iceberg, but they have different strengths:
| Dimension | Apache Flink | Spark Structured Streaming |
|---|---|---|
| Latency | Sub-second (true streaming) | Seconds to minutes (micro-batch) |
| Exactly-once | Native, checkpoint-based | Available but more complex |
| CDC support | Native Debezium connector | Via Spark + Kafka + custom logic |
| State management | Built-in, production-grade | Limited for complex stateful ops |
| Python API | PyFlink (less mature) | PySpark (very mature) |
| Iceberg UPSERT | Native sink support | Less mature UPSERT support |
Summary
Apache Flink is the streaming ingestion engine of the modern data lakehouse. Its native Apache Iceberg sink, exactly-once semantics, and deep CDC integration capabilities make it the optimal choice for organizations that need data freshness measured in seconds rather than hours. In the lakehouse engine stack, Flink ingests real-time data, Spark processes large batch transformations, and Dremio serves the resulting Iceberg tables to analysts — each engine optimized for its specific workload.