What Is Apache Iceberg?
Apache Iceberg is an open-source, high-performance table format for organizing large analytical datasets in cloud object storage. It acts as the metadata and transactional layer that sits between raw data files (Apache Parquet, ORC, or Avro) and the query engines that process them — transforming a disorganized collection of files in S3 or ADLS into a fully governed, ACID-compliant database table.
Iceberg was originally developed at Netflix by engineers Ryan Blue and Daniel Weeks, who needed a better way to manage petabyte-scale datasets on S3 that were growing too large for Hive's partition-based metadata model. After open-sourcing Iceberg and donating it to the Apache Software Foundation in 2018, it grew rapidly to become the industry-standard open table format, with support from every major cloud provider, query engine, and data platform vendor.
At its core, Iceberg solves four problems that the data lake's raw file storage cannot address: ACID transactions for safe concurrent reads and writes, schema evolution for changing table structure without rewriting data, time travel for querying historical table states, and multi-engine interoperability through an open specification that any engine can implement.
As of 2025, Apache Iceberg has won the open table format convergence. Delta Lake supports reading Iceberg via UniForm. Apache Hudi is adding Iceberg compatibility. Every major cloud provider offers native Iceberg support. The Iceberg REST Catalog specification has become the catalog API standard. Understanding Apache Iceberg is now a foundational skill for every data engineer.
The Apache Iceberg Metadata Architecture
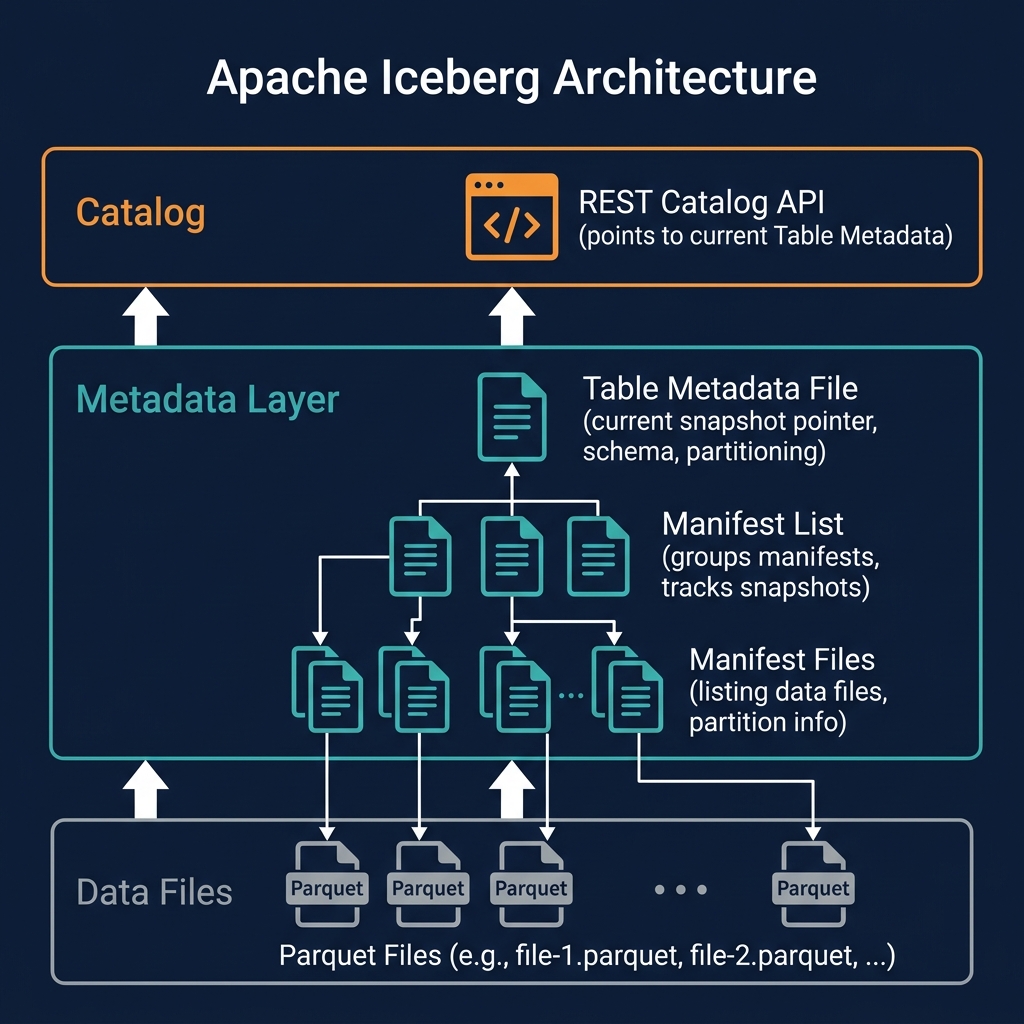
Iceberg's power comes from its metadata architecture — a three-level tree of files that tracks every data file in the table and every change ever made to it.
Level 1: Data Files
At the base are the actual data files — immutable Parquet, ORC, or Avro files stored in cloud object storage. Each data file contains a subset of the table's rows in columnar format, with embedded column statistics (min/max values, null counts, row counts) used for data skipping.
Level 2: Manifest Files
Manifest files are Avro files that list the data files belonging to a specific snapshot, along with each file's column-level statistics and partition information. A single manifest file tracks thousands of data files. Manifest files are the primary mechanism for partition pruning — a query engine reads a manifest to determine which data files are in the relevant partition range, then reads only those files.
Level 3: Manifest Lists
A manifest list (also called a snapshot file) is a file that groups together all the manifest files belonging to a specific table snapshot. Each committed transaction creates a new manifest list, making it the boundary between snapshots. The manifest list also records high-level summary statistics for each manifest — enabling aggressive pruning at the manifest level before even reading individual manifest files.
Table Metadata File
The table metadata file (a JSON file) is the root of the entire metadata tree. It records: the table's current snapshot (pointer to the current manifest list), the table's schema history, the partition specification history, the sort order, and pointers to all historical snapshots. The catalog holds a pointer to the current table metadata file — atomically updating this pointer is the commit mechanism for all Iceberg transactions.
Apache Iceberg Specification Versions
The Iceberg specification has two major versions in active use:
Iceberg V1
The original Iceberg specification supports: ACID transactions, schema evolution, partition evolution, hidden partitioning, time travel, and file-level statistics. V1 is fully supported by all Iceberg-compatible engines and is appropriate for tables that do not require row-level delete operations.
Iceberg V2
The V2 specification, ratified in 2021, adds support for row-level deletes and updates through two new file types: positional delete files (identifying rows to delete by their position within data files) and equality delete files (identifying rows to delete by column value matches). V2 also changes the row lineage tracking requirements for delete operations, enabling more efficient merge-on-read implementations.
V2 is required for any table that needs efficient UPDATE, DELETE, or MERGE INTO operations without rewriting entire data files. All modern Iceberg-compatible engines support V2. When creating new tables in Dremio, Spark, or Trino, V2 is typically the default format version.
Iceberg V3 (In Development)
The V3 specification, under active development, will add: native support for the Variant data type (for semi-structured JSON data within Iceberg tables), improved deletion file merging, and streaming write protocol enhancements. V3 represents Iceberg's evolution toward supporting AI-native and real-time workloads natively within the format specification.
Key Apache Iceberg Features
Iceberg's feature set is what makes it the definitive choice for the modern data lakehouse:
ACID Transactions
Iceberg provides serializable isolation for writers and snapshot isolation for readers. The atomic metadata pointer swap in the catalog is the transaction commit — no partial states are visible. See ACID Transactions for the full implementation detail.
Schema Evolution
Schema evolution allows adding, dropping, renaming, reordering, and widening column types without rewriting data files. Iceberg tracks each column by a unique integer ID rather than by name — preventing silent data corruption when columns are renamed at the source.
Partition Evolution
Partition evolution allows changing the table's partitioning scheme — from daily to hourly, or from hash-bucketing to range partitioning — without rewriting historical data. New data uses the new partition scheme; old data retains its original partitioning. Query engines read both correctly.
Hidden Partitioning
Hidden partitioning applies partition transforms (bucket, truncate, date extraction) automatically, without requiring the query writer to know or filter on partition column values. Queries like WHERE event_time > '2026-01-01' automatically benefit from partition pruning when the table is partitioned by days(event_time), even though event_time is not a partition column in name.
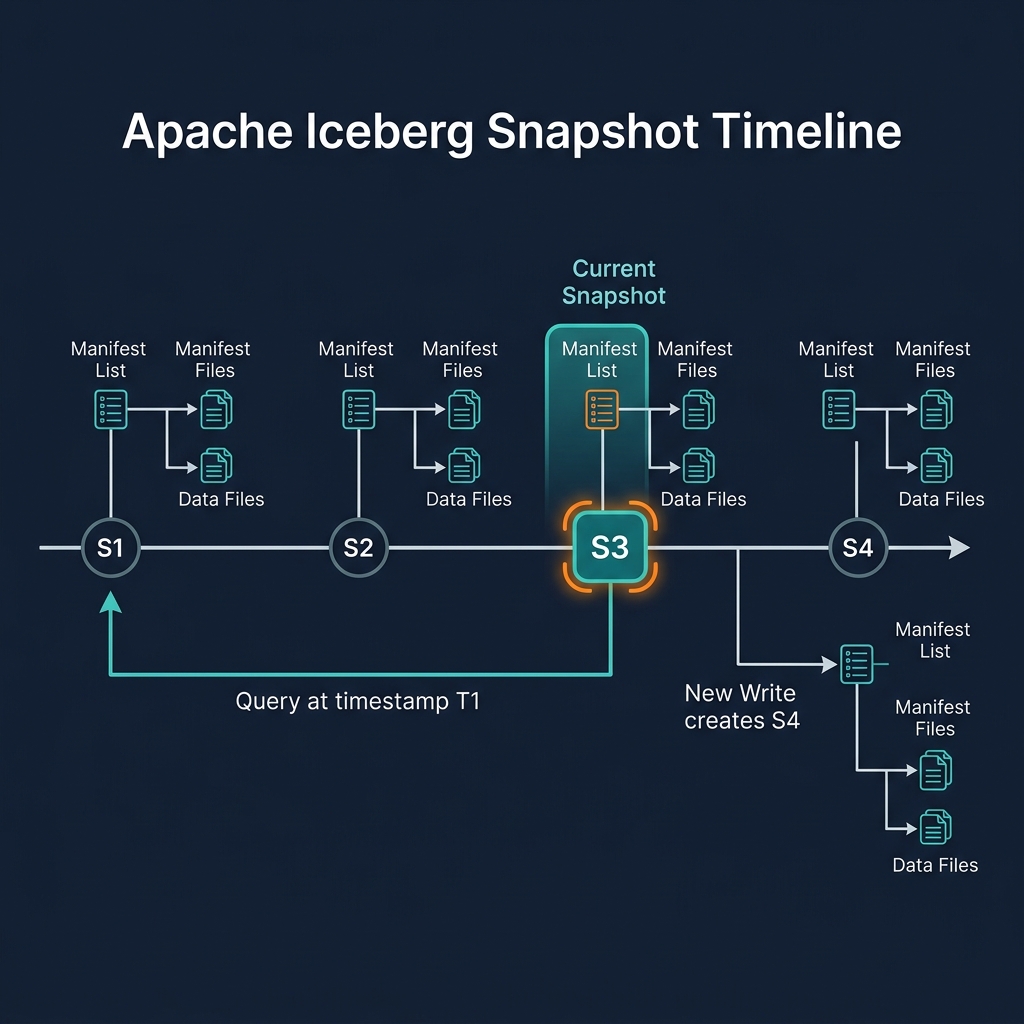
Time Travel
Time travel queries reference historical snapshots by snapshot ID or timestamp, enabling point-in-time analysis and audit queries without separate data copies.
Row-Level Operations (V2)
V2 enables efficient row-level deletes and updates using delete files rather than full partition rewrites, supporting GDPR erasure, CDC upserts, and SCD type 2 implementations efficiently.
The Iceberg REST Catalog Specification
Beyond the table format itself, the Iceberg project has defined the Iceberg REST Catalog specification — an open HTTP API standard for catalog operations. This specification defines endpoints for: creating and listing namespaces, creating, listing, and dropping tables, loading table metadata, committing transactions, and managing access tokens.
Any catalog system that implements this REST API can serve as an Iceberg catalog. Any query engine that implements the REST catalog client can connect to any compliant catalog. This bidirectional openness creates a genuinely interoperable ecosystem: you can mix and match catalog implementations and query engines without vendor coupling.
Major REST catalog implementations include Apache Polaris (donated by Snowflake, now ASF), Project Nessie (Dremio's Git-like catalog), AWS Glue (native Iceberg REST support), and Tabular (now part of Databricks). All major Iceberg-compatible engines — Dremio, Spark, Trino, Flink — implement the REST catalog client, enabling plug-and-play catalog interoperability.
Apache Iceberg vs. Delta Lake vs. Apache Hudi
The three major open table formats differ in design philosophy, governance, and ecosystem support:
| Dimension | Apache Iceberg | Delta Lake | Apache Hudi |
|---|---|---|---|
| Governance | Apache Software Foundation | Linux Foundation | Apache Software Foundation |
| Origin | Netflix (2017) | Databricks (2019) | Uber (2016) |
| Engine support | Broadest (all major engines) | Strong (Databricks-centric) | Moderate (Spark, Flink) |
| Catalog standard | Iceberg REST Catalog API | HMS / Unity Catalog | Hive Metastore |
| Row-level deletes | V2 delete files (efficient) | Delta log (efficient) | Native specialty |
| Schema evolution | Full (add/drop/rename/reorder) | Full | Full |
| Cloud warehouse support | All major warehouses | Via UniForm | Limited |
| Best for | General lakehouse (default choice) | Databricks shops | High-freq CDC streams |
Verdict for 2025: Apache Iceberg is the default choice for new lakehouses. Its governance neutrality, REST catalog standard, and breadth of engine support make it the most future-proof option. Delta Lake remains viable for Databricks-centric organizations. Hudi retains a niche for ultra-high-frequency streaming CDC workloads.
Apache Iceberg Ecosystem and Integrations
The Apache Iceberg ecosystem has expanded dramatically since 2022:
Query Engines
- Dremio: Native Iceberg table format, full DML, automated optimization, Open Catalog
- Apache Spark: Most complete Iceberg write support, including all V2 operations
- Trino / Presto: Strong read and write support; preferred for federated SQL across multiple catalogs
- Apache Flink: Streaming writes to Iceberg from Kafka/CDC pipelines
- StarRocks / Apache Doris: OLAP engines with Iceberg read support for real-time analytics
Cloud Provider Integration
- AWS: S3 Table Buckets (native Iceberg in S3), Athena, Glue Catalog, EMR, SageMaker
- Google Cloud: BigLake (Iceberg tables in GCS queryable from BigQuery)
- Microsoft Azure: ADLS Gen2 + Azure Databricks + Synapse Analytics
Catalogs
- Apache Polaris: ASF-governed, vendor-neutral REST catalog
- Project Nessie: Git-like branching and tagging for Iceberg tables
- AWS Glue: Managed catalog with Iceberg REST API
AI and ML
- PyIceberg: Python library for reading/writing Iceberg tables from ML workloads
- MLflow: Experiment tracking integrated with Iceberg feature tables
Writing to Apache Iceberg Tables
Iceberg supports four write patterns, each appropriate for different workload characteristics:
Append
New data files are added to the table. A new snapshot is created containing all previous files plus the new ones. This is the cheapest write operation — no existing files are modified. Used for Bronze ingestion, event log tables, and any append-only workload.
Overwrite
Selected partitions are replaced entirely. Existing files in the overwritten partition are removed from the new snapshot; new files replace them. Used for full-partition refresh patterns and batch ETL that replaces daily partitions.
Copy-on-Write (CoW)
UPDATE and DELETE operations rewrite affected data files entirely, producing new files with the changes applied and excluding deleted rows. The new snapshot references the new files; old files become orphaned (accessible via time travel). Optimized for read-heavy workloads where write frequency is low.
Merge-on-Read (MoR)
UPDATE and DELETE operations write small delete files (positional or equality) rather than rewriting data files. The query engine merges delete files with data files at read time to produce the correct result. Optimized for write-heavy workloads like high-frequency CDC where full file rewrites are too expensive.
Reading Apache Iceberg Tables
Reading an Iceberg table follows a consistent process that every compliant query engine implements:
- Catalog lookup: The engine asks the catalog for the current table metadata file location
- Metadata read: The engine reads the JSON table metadata file, identifying the current snapshot and schema
- Manifest list read: The engine reads the current snapshot's manifest list, getting a list of all manifest files and their partition-level statistics
- Manifest pruning: Based on the query's filter predicates, the engine eliminates manifests whose partition ranges cannot contain relevant rows
- Manifest file reads: The engine reads the relevant manifest files, getting a list of data files and their column-level statistics
- File-level pruning: The engine eliminates data files whose min/max statistics prove they contain no relevant rows
- Data file reads: The engine reads only the relevant data files, applying column projection (reading only queried columns) and row filtering
This multi-level pruning — at the manifest list, manifest file, and data file level — is what makes Iceberg queries fast on large tables. A table with 10 million data files can often be answered by reading fewer than 100 files, skipping 99.999% of storage I/O.
Apache Iceberg with Dremio
Dremio treats Apache Iceberg as its native table format — not a compatibility layer, but the foundational storage model for the entire platform. This deep integration enables capabilities that go beyond basic Iceberg compliance:
- Full SQL DML: INSERT INTO, UPDATE, DELETE, MERGE INTO using ANSI SQL against any Iceberg table
- Time travel:
SELECT * FROM table AT SNAPSHOT 'id'andAT TIMESTAMP 'datetime' - Reflections on Iceberg: Materialized acceleration built on Iceberg tables, transparently selected by Dremio's optimizer
- Automated Table Optimization: Background compaction, clustering, and orphan file cleanup without manual intervention
- Open Catalog: Iceberg REST Catalog implementation accessible by any engine, not just Dremio
- Multi-engine safety: Dremio correctly handles Iceberg tables written by Spark or Flink — reading the current committed snapshot regardless of which engine last wrote
For organizations building on Apache Iceberg, Dremio is the query engine that unlocks the full potential of the format — from sub-second BI queries via Reflections to AI agent data access via the MCP server.
Summary
Apache Iceberg is the foundational technology of the modern data lakehouse. Its three-level metadata architecture (table metadata → manifest lists → manifest files → data files) delivers ACID transactions, schema evolution, partition evolution, time travel, and multi-engine interoperability on top of cheap, open cloud object storage.
With the Iceberg REST Catalog specification standardizing catalog interoperability, native support from every major cloud provider and query engine, and its ASF governance model ensuring vendor neutrality, Apache Iceberg has won the open table format era. It is now the default choice for any new data lakehouse project — and the migration target for organizations moving away from proprietary cloud data warehouses.
Platforms like Dremio have built comprehensive lakehouse products on top of Iceberg, demonstrating that open-format data is fully capable of powering enterprise-grade analytics, governance, and increasingly, AI agent workloads.