What Is Dremio?
Dremio is a cloud-native data lakehouse platform that provides the full analytics stack on top of your own cloud object storage: a high-performance SQL query engine, an AI-powered semantic layer, materialized query acceleration via Reflections, an open Apache Iceberg catalog, and federated query capability across heterogeneous data sources — all without requiring data to be moved into a proprietary storage format.
Founded in 2015 and headquartered in Santa Clara, California, Dremio was built specifically for the decoupled storage-and-compute paradigm. Its core design principle is that data should live in open format on cloud storage you own, and that the query engine should bring intelligence to that data rather than requiring data to be imported into a proprietary store.
Dremio's platform has three primary use cases: BI and self-service analytics (connecting Tableau, Power BI, Looker, and other tools to Iceberg data with sub-second response times via Reflections), data engineering (creating and managing Iceberg tables, running MERGE INTO for CDC pipelines, and optimizing table layouts), and AI-ready data access (exposing a semantic layer and MCP server for AI agents to discover and query enterprise data autonomously).
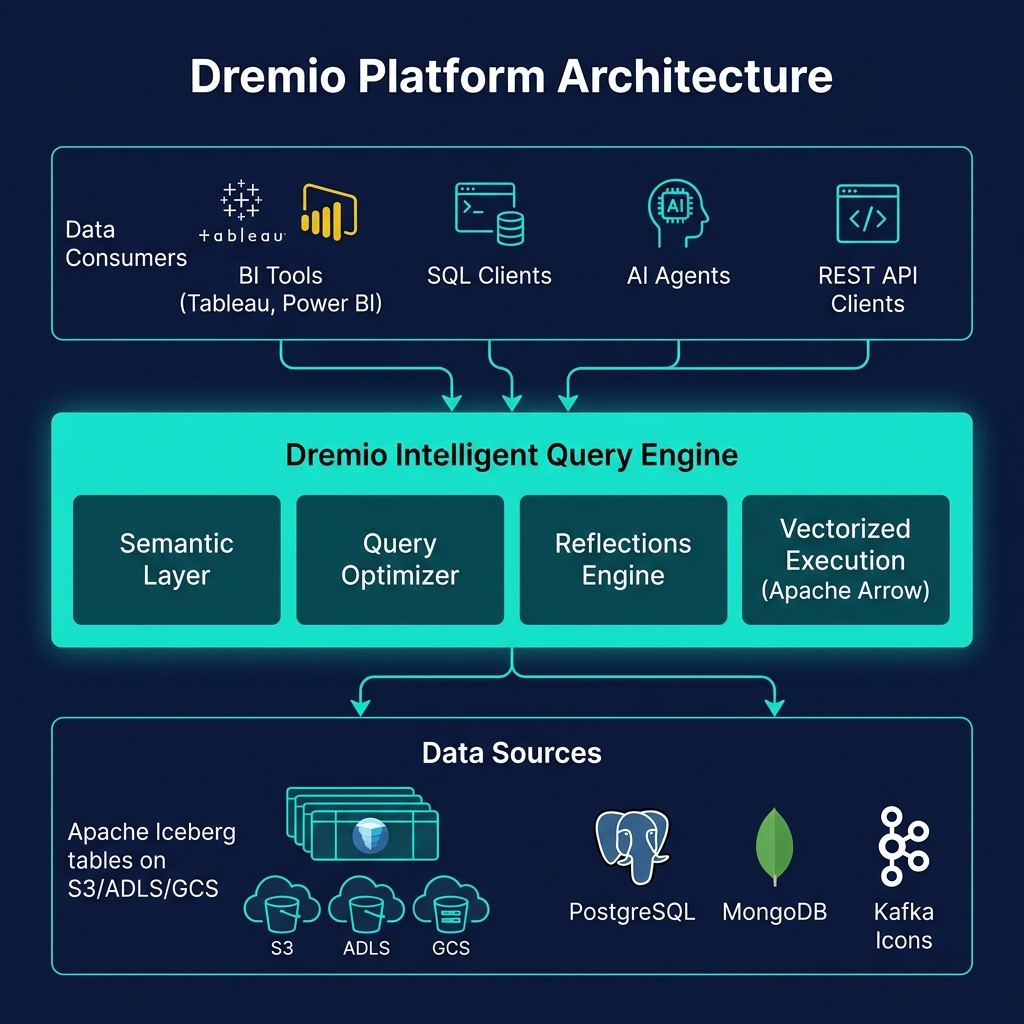
Core Dremio Architecture
Dremio's architecture has four integrated layers:
Intelligent Query Engine
Built on Apache Arrow for vectorized, columnar in-memory processing, Dremio's query engine reads Iceberg metadata aggressively to minimize data scanned from object storage. Its optimizer applies predicate pushdown, column pruning, and Reflection matching before issuing any storage reads.
AI Semantic Layer
Dremio's semantic layer — built on Virtual Datasets, wikis, labels, and business metric definitions — translates raw Iceberg tables into business-friendly views. The AI Semantic Layer extends this with natural language understanding, allowing business users and AI agents to query data in business terms rather than technical SQL.
Reflections
Reflections are Dremio's materialized query acceleration technology. They pre-compute aggregations and raw-scan optimizations as Iceberg tables, and the query optimizer automatically routes incoming queries to the appropriate Reflection — delivering sub-second BI performance without any BI tool configuration changes.
Open Catalog
Dremio's Open Catalog implements the Iceberg REST Catalog specification, powered by Project Nessie for Git-like branching and tagging of Iceberg tables. Any engine implementing the REST catalog client can use Dremio's catalog.
Dremio Cloud vs. Dremio Software
Dremio is available in two deployment models:
Dremio Cloud
Dremio Cloud is the fully managed SaaS offering on AWS and Azure. Dremio manages all infrastructure — compute engines, coordinators, catalog, and monitoring. Users connect their own cloud storage (S3 or ADLS), and Dremio's managed engines query it. Dremio Cloud offers a consumption-based pricing model (pay for compute used) and auto-scaling compute engines that spin up in seconds.
Dremio Software (Self-Hosted)
Dremio Software is deployed by the customer in their own cloud environment (typically on Kubernetes). The customer manages the infrastructure; Dremio provides the software. This model gives maximum control over security, networking, and configuration. Dremio Community Edition is a free version of Dremio Software suitable for evaluation and small-scale production deployments.
Dremio and Apache Iceberg
Dremio's deepest technical integration is with Apache Iceberg. Iceberg is Dremio's native table format — not a compatibility layer, but the foundational storage model for the entire platform:
- Full ANSI SQL DML: INSERT, UPDATE, DELETE, MERGE INTO against Iceberg tables
- Time travel: AT SNAPSHOT and AT TIMESTAMP query syntax
- Table rollback: revert to any historical Iceberg snapshot
- Automated table optimization: compaction, Z-ordering, orphan file cleanup
- Schema evolution: ADD COLUMN, DROP COLUMN, RENAME COLUMN via SQL DDL
- Reflections on Iceberg: materialized acceleration stored as Iceberg tables
Dremio's Open Source Contributions
Dremio is one of the largest contributors to the open lakehouse ecosystem. Key open-source contributions include: Project Nessie (Git-like catalog for Iceberg, donated to the open-source community and powering multiple catalog implementations), Apache Polaris (co-developed with Snowflake, now ASF-governed), and Apache Arrow (Dremio engineers are core committers to Arrow, the columnar memory format that powers Dremio's vectorized execution and the Arrow Flight SQL protocol).
Dremio Connectivity and Integrations
Dremio provides comprehensive connectivity for every type of data consumer:
- BI Tools: ODBC and JDBC drivers for Tableau, Power BI, Looker, MicroStrategy, Qlik, and all standard SQL clients
- Arrow Flight SQL: High-performance binary protocol for Python, R, and application-level data access at 10–100x JDBC throughput
- REST API: SQL job submission and result retrieval for application integration
- dbt adapter: Run dbt models against Dremio's engine, creating Iceberg tables in Dremio's catalog
- MCP Server: Model Context Protocol server for AI agent data discovery and query access
- Federated sources: Connect PostgreSQL, MySQL, MongoDB, Elasticsearch, S3 files, and more as queryable sources alongside Iceberg tables
Summary
Dremio is the most complete open data lakehouse platform available in 2025 — combining a high-performance Iceberg query engine, AI semantic layer, Reflections acceleration, and an open catalog in a single cohesive product. Its commitment to open standards (Apache Iceberg, Apache Arrow, Iceberg REST Catalog) means organizations retain data ownership and engine flexibility while getting enterprise-grade performance and governance. For teams building on the data lakehouse, Dremio is the query engine, semantic layer, and catalog platform that brings it all together.