What Is Apache Hudi?
Apache Hudi (Hadoop Upserts Deletes and Incrementals) is an open-source data management framework that provides efficient upsert, delete, and incremental read capabilities on top of cloud object storage. Developed at Uber to solve the challenge of syncing changes from production databases into their data lake at scale, Hudi was donated to the Apache Software Foundation in 2019.
Hudi's design philosophy differs from Apache Iceberg and Delta Lake in a fundamental way: while Iceberg and Delta are primarily table formats optimized for general-purpose ACID analytics, Hudi is a data management framework that includes the table format, the write client library, the CDC ingestion framework, and the incremental processing API as an integrated system. This comprehensive approach makes Hudi more opinionated and more tightly coupled to the Spark ecosystem, but also more purpose-built for its target use case: high-frequency, record-level CDC from operational databases.
At Uber, Hudi's core use case was syncing billions of rows of ride, driver, and payment data from production MySQL databases into a Hadoop-based data lake, with record-level updates applied within minutes of the source change. This CDC-at-scale requirement drove Hudi's design: an index system for efficient record lookup, a timeline model for tracking operations, and two table types optimized for different read/write trade-offs.
Hudi's Key Concepts: Timeline, Table Types, and Index
Three concepts define how Hudi works: the timeline, table types, and the index.
The Hudi Timeline
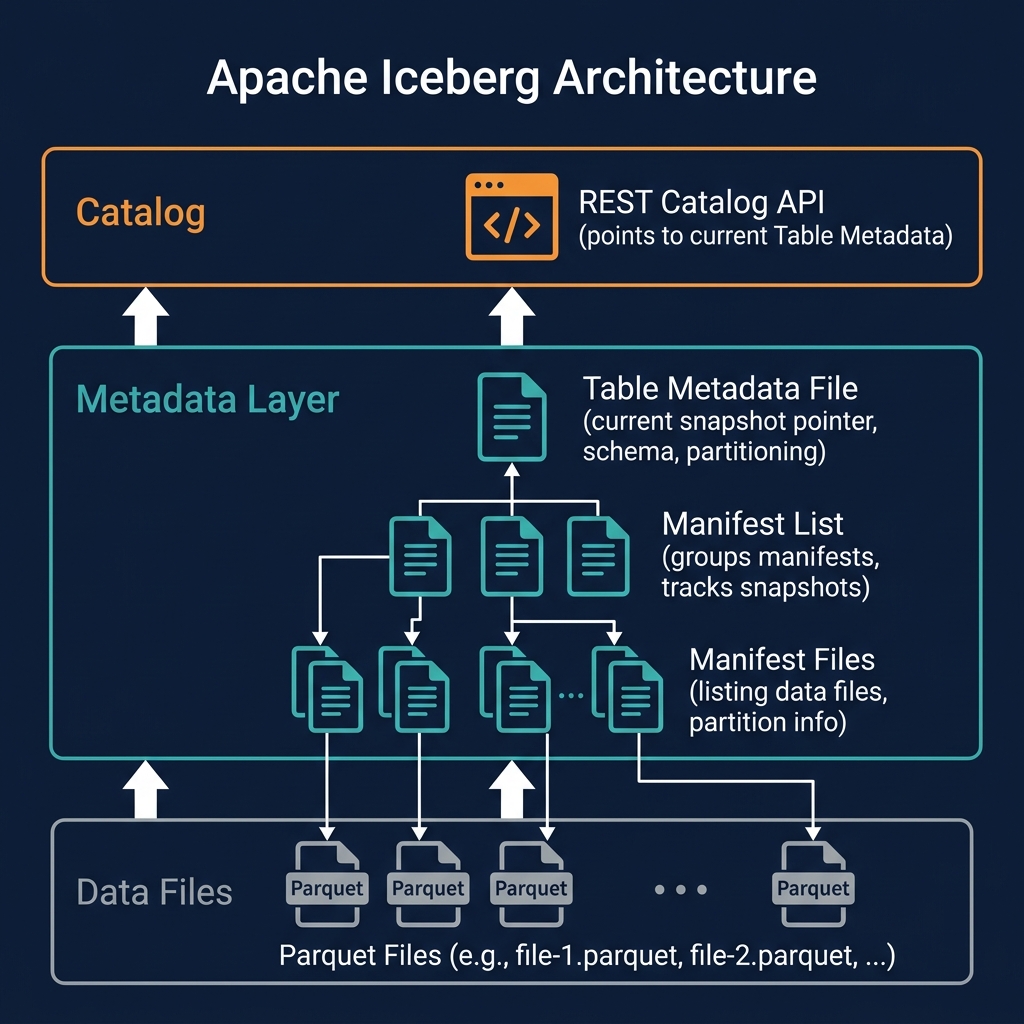
Hudi maintains a timeline of all operations performed on a table, stored in a .hoodie metadata folder alongside the data. Each timeline entry records an operation (commit, delta commit, compaction, clean, rollback) with its timestamp and status (requested, inflight, completed). This timeline is the equivalent of Iceberg's snapshot log — it provides the transactional history, enables time travel, and coordinates concurrent writes.
Copy-on-Write (CoW) Table Type
In a Copy-on-Write table, all upsert and delete operations rewrite the affected base files during the write operation itself. Reads are always fast because there are no delete files to merge — all files are clean, updated Parquet files. Writes are more expensive because they involve reading and rewriting affected base files. CoW is optimal for tables where reads significantly outnumber writes.
Merge-on-Read (MoR) Table Type
In a Merge-on-Read table, upserts write to small delta log files (in Avro format) alongside the base Parquet files rather than rewriting them. Writes are very fast because they only append to the delta log. Reads must merge the delta log with the base files at query time to produce the correct result. MoR is optimal for tables with frequent writes — particularly streaming CDC workloads — where CoW's file rewriting would create too much write amplification. Periodic compaction merges the delta log files into updated base Parquet files, restoring read performance.
The Hudi Index
Hudi's index is the capability that sets it apart from other table formats for CDC workloads. When an upsert arrives (a new version of an existing record), Hudi uses the index to quickly locate which data file contains the existing record, avoiding a full table scan. Index implementations include Bloom filter (in-memory, approximate), HBase-backed (external, exact), and record-level index (in-memory, exact, introduced in Hudi 0.14). The index makes record-level upserts practical at petabyte scale — without it, finding the right file to update would require scanning the entire table.
Hudi vs. Iceberg vs. Delta Lake
The three open table formats occupy distinct positions in the ecosystem:
| Dimension | Apache Hudi | Apache Iceberg | Delta Lake |
|---|---|---|---|
| Primary strength | High-frequency CDC upserts | General-purpose analytics | Databricks ecosystem |
| Governance | Apache Software Foundation | Apache Software Foundation | Linux Foundation |
| Write model | CoW or MoR with index lookup | CoW or MoR with delete files | CoW or MoR with log |
| Engine support | Spark, Flink (primary) | All major engines | Spark, Databricks (primary) |
| Catalog interop | Hive Metastore primarily | Iceberg REST Catalog (standard) | Unity Catalog / HMS |
| Streaming ingestion | Best-in-class | Good (improving with V3) | Good |
| Query performance | Good (with compaction) | Excellent | Excellent (Photon) |
| Best use case | CDC streaming to lakehouse | General lakehouse, multi-engine | Databricks analytics |
Key takeaway: If your primary workload is high-frequency CDC from operational databases (thousands of upserts per second), Hudi's index mechanism provides genuine performance advantages over Iceberg. For all other use cases, Apache Iceberg is the preferred choice in 2025.
Hudi's CDC Ingestion Capability
Hudi's most distinctive capability is its native, optimized support for Change Data Capture (CDC) ingestion. The Hudi DeltaStreamer (now called HoodieStreamer) is a production-grade streaming ingestion utility that continuously reads CDC events from Apache Kafka and applies them to Hudi tables with exactly-once semantics.
The CDC ingestion flow with Hudi works as follows: a CDC connector (Debezium for MySQL, Postgres, MongoDB) publishes change events (insert, update, delete) to Kafka topics. HoodieStreamer reads these Kafka events, applies the Hudi index to resolve existing record locations, and writes the changes to the Hudi table — inserts go to new files, updates patch existing files via MoR delta logs, and deletes are recorded as tombstones. Compaction runs periodically to merge delta logs and restore read performance.
This end-to-end CDC pipeline, running on Apache Spark with Hudi, can process hundreds of thousands of record-level operations per second and deliver data to the analytical table within minutes of the source change — competitive with dedicated streaming platforms for CDC use cases.
Hudi Incremental Queries
One of Hudi's unique capabilities is its incremental query mode — the ability to query only the records that changed between two points in time. This is distinct from time travel (which queries the entire table as of a historical point) — incremental queries return only the delta of changes within a specified time range.
Incremental queries are expressed as: SELECT * FROM hudi_table WHERE _hoodie_commit_time > '20260101000000' AND _hoodie_commit_time <= '20260102000000'. Hudi returns only the records committed during that window — inserts, updates (returning the latest version), and deletes (optionally).
This capability is particularly powerful for building efficient downstream processing pipelines. Instead of scanning the entire table to find what changed since the last processing run, downstream consumers can efficiently pull only the changed records from Hudi. This "change feed" pattern eliminates the need for watermark-based full scans that are common in Spark incremental pipelines on non-Hudi formats.
Apache Iceberg is adding comparable incremental read capabilities through its incremental_append_scan and incremental_change_scan APIs, narrowing Hudi's advantage in this area. But Hudi's incremental query maturity is still ahead of Iceberg's as of 2025.
Hudi Concurrency and Multi-Writer Support
Hudi supports multiple concurrent writers through its multi-writer protocol, using optimistic concurrency control similar to Iceberg. Each writer operates on the table independently and commits when done; if two writers committed conflicting changes, Hudi's conflict detection mechanism identifies the conflict and rolls back the losing writer's changes, forcing a retry.
However, Hudi's multi-writer support is primarily designed for Spark batch writers, not for mixed engine environments (Spark + Trino + Dremio). Hudi's table format is most fully implemented in the Spark ecosystem, and while Hudi provides read support for Trino and Presto, write support from non-Spark engines is limited.
This ecosystem constraint is Hudi's most significant limitation relative to Apache Iceberg: Iceberg's REST Catalog specification and comprehensive multi-engine write support make it genuinely engine-agnostic. Hudi's strength — its deep Spark integration and index mechanism — is inseparable from its constraint: tight Spark coupling limits its utility in multi-engine lakehouses.
Hudi Table Maintenance: Compaction and Cleaning
Like all open table formats, Hudi tables require regular maintenance to remain performant. The two primary maintenance operations are compaction and cleaning.
Compaction
Compaction is essential for MoR tables. As delta log files accumulate from frequent upsert writes, read performance degrades — every query must merge the base files with all delta logs. Compaction merges delta logs into new base Parquet files, restoring read performance. Hudi supports both synchronous compaction (blocking writes during compaction) and asynchronous compaction (compacting a previous snapshot while writes continue). Asynchronous compaction is preferred for production pipelines to avoid write latency spikes.
Cleaning
Hudi's cleaner removes old file versions that are no longer needed for time travel or ongoing queries. The cleaner is configured with a retention policy (keep N commits, keep N hours) and runs automatically after each commit by default. Proper cleaning is essential for preventing storage cost growth from accumulating old file versions.
Clustering
Hudi's clustering operation (similar to Iceberg's Z-ordering) reorganizes data files to optimize the data layout for common query patterns — co-locating records with similar values in the same files to maximize data skipping effectiveness. Unlike compaction (which merges delta logs), clustering reorganizes base files and is applicable to both CoW and MoR table types.
Hudi Ecosystem: Engines and Catalogs
Hudi's ecosystem is less broad than Iceberg's but well-established within the Spark and Flink communities:
Query Engine Support
- Apache Spark: The most complete Hudi support — full read and write, CoW and MoR, all compaction and clustering operations, DeltaStreamer/HoodieStreamer
- Apache Flink: Strong streaming write support — Flink is increasingly used as the ingestion engine for real-time CDC pipelines into Hudi
- Trino / Presto: Read support for CoW and MoR tables (with snapshot read for MoR); limited write support
- Hive: Read support through Hudi's InputFormat
- AWS Athena: Read support for Hudi tables in S3
Catalog Support
Hudi primarily uses the Hive Metastore for catalog management, though the Hudi project has been adding Iceberg REST Catalog compatibility through its Hudi Catalog Service project. Full Iceberg REST Catalog compatibility remains a work in progress as of 2025.
Cloud Provider Integration
AWS is the primary cloud with native Hudi support: EMR includes Hudi libraries, Glue jobs can write Hudi tables, and Athena can query them. Azure and GCP support Hudi on Spark but without the same level of native service integration as AWS.
Hudi at Uber and Other Large-Scale Deployments
Hudi's production credibility comes from Uber's massive-scale deployment. Uber's data engineering team built and operates one of the largest Hudi deployments in the world: thousands of Hudi tables, petabytes of data, and hundreds of CDC pipelines syncing real-time changes from production databases.
Key Uber use cases include: syncing the riders table (hundreds of millions of rows) from MySQL to Hudi with record-level updates applied within 5 minutes of the source change; syncing the trips table with complex event merging (multiple updates per trip as status changes); and incremental processing of change data for downstream machine learning feature pipelines.
Other major Hudi adopters include Robinhood (financial transaction CDC), ByteDance (TikTok's parent, social media event processing), and several large financial institutions with high-frequency trading and customer data synchronization requirements.
These deployments validate Hudi's technical claims for high-frequency CDC workloads. However, the common thread among Hudi's largest adopters is Spark as the primary compute platform — reinforcing the point that Hudi's strengths are most fully realized in Spark-centric architectures.
When to Choose Apache Hudi
Given the 2025 landscape where Apache Iceberg has emerged as the general-purpose standard, the cases for choosing Hudi are specific:
- Ultra-high-frequency CDC: If your workload involves syncing thousands of record-level changes per second from operational databases with strict latency requirements (sub-5-minute freshness), Hudi's index mechanism provides genuine performance advantages over Iceberg's current V2 implementation.
- Spark-centric organization: If Apache Spark is your primary and only compute engine, Hudi's tight Spark integration provides a more optimized experience than Iceberg for write-heavy workloads.
- Incremental processing pipelines: If your downstream processing relies heavily on incremental change feeds (what changed since the last run?), Hudi's mature incremental query API provides a cleaner developer experience than Iceberg's current incremental scan implementation.
- Existing Hudi investment: Organizations already running production Hudi deployments should evaluate migration to Iceberg carefully — Hudi's CDC performance advantages may justify staying on Hudi even as Iceberg improves.
For all other use cases, including new greenfield lakehouses, multi-engine environments, and organizations using Dremio as their primary query engine, Apache Iceberg is the better choice.
Summary
Apache Hudi was a pioneering open table format that solved the real, production-scale problem of high-frequency CDC ingestion at Uber. Its index-based upsert mechanism, dual table type design, incremental query API, and streaming ingestion framework (HoodieStreamer) represent genuine innovations that influenced the design of subsequent table formats.
In the 2025 open table format landscape, Hudi occupies a specialist position: the preferred format for workloads with extreme CDC update frequencies where Iceberg's current MoR implementation is insufficient. For general-purpose lakehouse deployments, Apache Iceberg's broader engine support, REST Catalog standard, and superior ecosystem make it the default choice.
Organizations evaluating Hudi should assess whether their specific workload characteristics — CDC update frequency, required freshness, engine ecosystem — genuinely benefit from Hudi's specialty features before accepting the trade-off of narrower engine support and more limited catalog interoperability.