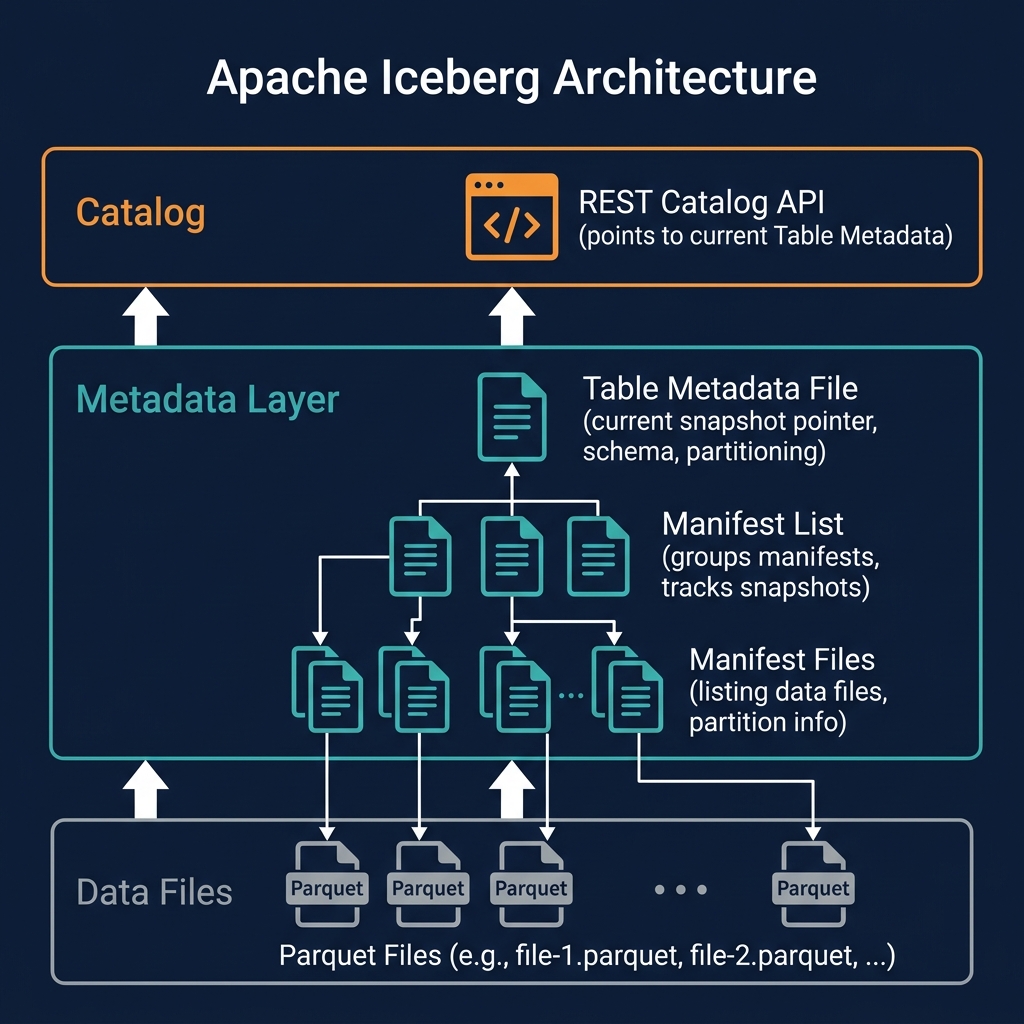
What Is Compaction?
Compaction is a maintenance operation that rewrites Apache Iceberg table files to improve query performance and reduce storage overhead. Over time, as data is continuously ingested in small batches — from streaming pipelines, frequent micro-batch ETL jobs, or frequent MERGE INTO operations — a table accumulates many small Parquet files. Each small file requires a separate I/O request from object storage, making queries that read many files slow and expensive.
Compaction addresses this by reading many small files and rewriting their contents into fewer, larger, optimally sized files — typically targeting 128MB to 512MB of compressed Parquet per file. The result is fewer files to open, less metadata to read, and faster sequential reads from object storage.
Beyond simple file merging, compaction in Iceberg can also: rewrite Merge-on-Read delete files into clean data files (eliminating the merge overhead at query time); apply Z-ordering or sort orders to cluster data for common query patterns (improving data skipping effectiveness); and remove expired snapshot data files that are no longer referenced by any current snapshot.
Critically, Iceberg compaction is non-blocking: it runs concurrently with reader and writer queries without requiring table locks or downtime. It commits its result as a new Iceberg snapshot — readers see either the pre-compaction or the post-compaction snapshot, never an intermediate state.
Why Small Files Hurt Performance
The small file problem is one of the most common causes of Iceberg table performance degradation in production. It arises from several common patterns:
- Streaming ingestion: Apache Flink or Spark Structured Streaming writing micro-batches every 30 seconds produces 2880 files per day — each containing only a few seconds of data
- Frequent MERGE INTO: CDC pipelines running MERGE INTO every minute produce small delta files (in MoR mode) or small rewritten data files (in CoW mode)
- High-partition granularity: A table partitioned by
hours(event_time)with sparse data may have only a few rows per hour partition — each stored in a tiny file - Frequent schema changes: Adding columns produces new files; old small files are never merged
The performance impact is proportional to file count. A query that reads 10,000 small files (each 1MB) requires 10,000 HTTP requests to S3 and 10,000 file metadata reads — compared to 20 requests for 20 optimally sized 500MB files covering the same data. At scale, this difference translates to minutes vs. seconds of query latency.
Compaction Types in Apache Iceberg
Iceberg supports several distinct compaction operations:
Bin-Packing (Simple File Merge)
The most basic compaction: reads small files and groups them into target-sized output files (128MB–512MB). Uses a bin-packing algorithm to optimize the number of output files. Primarily addresses the small file problem without changing data ordering.
Sort-Based Compaction
Reads files, sorts all rows by specified sort columns, and writes sorted output files. Sorting enables aggressive data skipping for queries that filter on the sort columns — after sorting by customer_id, files contain contiguous ranges of customer IDs, and a query for a specific customer ID can skip all files whose customer_id range does not overlap.
Z-Order Compaction
Z-ordering (also called multi-dimensional clustering) interleaves the sort keys of multiple columns to optimize data layout for queries filtering on multiple dimensions simultaneously. A table Z-ordered by (region, product_category) allows efficient pruning for queries filtering on either or both dimensions.
MoR Delete File Compaction
For Merge-on-Read tables, compaction reads data files and their associated positional/equality delete files, applies the deletes, and writes new clean data files without the delete files. After this compaction, reads no longer need to apply delete files at query time, restoring CoW-equivalent read performance.
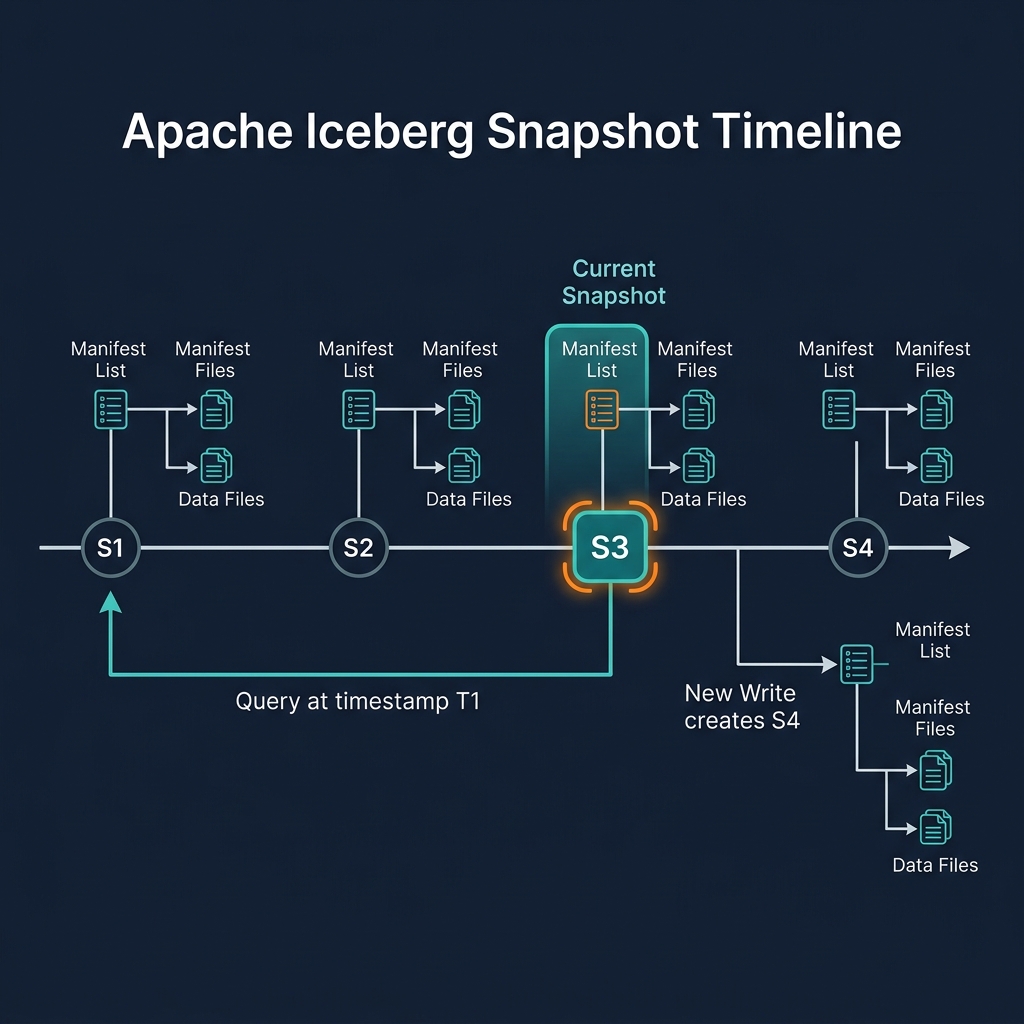
Compaction and Snapshot Lifecycle
Compaction interacts with Iceberg's snapshot lifecycle in an important way: after compaction produces new, optimized data files and commits them as a new snapshot, the old small files are no longer referenced by the current snapshot. However, they are still referenced by historical snapshots (for time travel purposes).
Old files become eligible for deletion only after the snapshots referencing them are expired. The typical maintenance sequence is: (1) run compaction to create new optimized files, (2) wait for the time travel retention window, (3) run expireSnapshots to remove old snapshots, (4) run remove_orphan_files to delete the old small files from object storage.
Skipping step 4 means old small files accumulate in storage indefinitely — a common operational mistake that leads to unbounded storage cost growth. Proper automated maintenance must include all four steps in sequence.
Dremio Automated Table Optimization
Dremio's Automated Table Optimization (ATO) is Dremio's built-in, zero-configuration compaction and maintenance system for Apache Iceberg tables. ATO continuously monitors Iceberg tables for maintenance needs and automatically performs compaction, Z-ordering, and orphan file cleanup — without requiring manual DBA intervention or scheduled Spark jobs.
ATO makes the following decisions autonomously: which tables need compaction (based on file count and size distribution), what target file size to use, whether to apply sort ordering or Z-ordering, and when to expire old snapshots and remove orphan files. The results are committed as new Iceberg snapshots — non-blocking and safe for concurrent queries.
This is one of Dremio's most significant operational advantages over Spark-based lakehouse setups, where compaction requires explicitly scheduling and monitoring Spark compaction jobs, tuning their configuration, and ensuring they complete before query performance degrades.
Compaction in Spark
For Spark-based lakehouses without Dremio's automated optimization, Iceberg provides the RewriteDataFiles action for programmatic compaction:
from pyiceberg.expressions import always_true
table.rewrite_data_files(
strategy='binpack', # or 'sort' or 'zorder'
sort_order=[SortField('customer_id')],
options={'target-file-size-bytes': str(512 * 1024 * 1024)}
)In Spark SQL: CALL catalog.system.rewrite_data_files(table => 'db.table', strategy => 'binpack'). These operations must be explicitly scheduled — typically as nightly or weekly Spark jobs in Apache Airflow — and monitored to ensure they complete successfully before the next write cycle accumulates new small files.
Compaction Best Practices
Effective compaction strategy requires tuning for specific workload patterns:
- Target file size: 256MB–512MB compressed Parquet is optimal for most analytical workloads. Smaller files increase metadata overhead; larger files reduce parallelism for fine-grained queries.
- Frequency: For streaming tables, compact at least daily (more frequently for very high-write-frequency tables). For batch tables, compact after each major load.
- Sort order: Apply sort-based compaction aligned with the most common query filter columns. A table frequently queried by
customer_idbenefits enormously from sort compaction oncustomer_id. - Z-order for multi-dimensional queries: Use Z-ordering for tables queried with variable filter combinations across 2–4 high-cardinality columns.
- Automate everything: Manual compaction is operationally fragile. Use Dremio's ATO, or implement automated scheduling via Airflow with proper monitoring and alerting on compaction job failures.
Summary
Compaction is an essential operational practice for any production data lakehouse built on Apache Iceberg. Without regular compaction, tables accumulate small files that progressively degrade query performance and inflate storage costs. With proper compaction — combining file merging, sort ordering, and lifecycle cleanup — Iceberg tables maintain optimal performance indefinitely as data accumulates.
Dremio's Automated Table Optimization handles all aspects of compaction automatically, making Dremio-managed lakehouse tables self-maintaining. For Spark-based pipelines, compaction must be explicitly scheduled and monitored — but Iceberg's non-blocking compaction model ensures that maintenance never disrupts concurrent analytical workloads.