What Is Data Mesh?
Data Mesh is an organizational and architectural paradigm for data management introduced by Zhamak Dehghani in her seminal 2019 article "How to Move Beyond a Monolithic Data Lake to a Distributed Data Mesh." It challenges the prevailing model of centralized data platforms — where a central data team owns, manages, and serves all of an organization's data — and proposes instead a decentralized model where domain teams own and serve their own data as products.
The Data Mesh paradigm emerged as a response to the scalability and organizational failures of centralized data platforms at large organizations. As data volumes grew and the number of data consumers expanded, central data teams became bottlenecks: domain teams waited weeks for pipeline changes, data quality issues in one domain affected all consumers, and the central team lacked the domain knowledge to build truly useful data products for every business unit.
Data Mesh borrows the organizational principles of software engineering — domain-driven design, team autonomy, platform thinking — and applies them to data. Just as microservices architecture distributed software development to autonomous teams while providing shared infrastructure, Data Mesh distributes data development to domain teams while providing a shared data infrastructure platform.
It is important to understand that Data Mesh is primarily an organizational paradigm, not a specific technology stack. It defines how responsibility for data is distributed across an organization. However, implementing Data Mesh effectively requires specific technological capabilities — particularly open table formats like Apache Iceberg, federated catalogs like Apache Polaris, and multi-engine query platforms like Dremio.
The Four Principles of Data Mesh
Data Mesh is defined by four core principles, each addressing a specific failure mode of centralized data platforms:
Principle 1: Domain-Oriented Decentralized Data Ownership
In a Data Mesh, data is owned, managed, and served by the domain team that produces it — not by a central data engineering team. The sales domain team owns and maintains the sales data. The customer experience domain owns the customer interaction data. The logistics domain owns the shipment and delivery data.
This is a direct application of Conway's Law: systems reflect the communication structures of the organizations that produce them. A central data team building pipelines for 15 domain teams will produce one monolithic pipeline system. Domain teams building their own pipelines will produce 15 smaller, more focused systems aligned with each domain's actual data model.
Principle 2: Data as a Product
In Data Mesh, each domain team is responsible for serving its data as a product — something that consumers in other domains can discover, understand, access, and rely upon. A data product has an owner accountable for its quality, documentation, and fitness for use. It has a stable, versioned interface (a schema contract). It has SLAs for freshness and availability. It is discoverable through a catalog.
This principle addresses one of the core failures of centralized platforms: data that exists technically but is unusable in practice because it lacks documentation, has poor quality, or changes without notice.
Principle 3: Self-Serve Data Infrastructure as a Platform
For domain teams to be self-sufficient data producers, they need infrastructure that makes it easy to build, test, deploy, and monitor data products without deep data engineering expertise. A central data platform team provides this infrastructure: the catalog, the query engine, the ingestion connectors, the governance tools, the monitoring dashboards — all packaged as a platform that domain teams can use without building from scratch.
Principle 4: Federated Computational Governance
Decentralizing ownership creates a governance risk: each domain might use different standards, schemas, security models, and quality practices, making cross-domain analysis impossible. Federated computational governance addresses this by defining and automatically enforcing global policies (data classification standards, retention policies, access control frameworks) through the platform, while giving domains autonomy over their domain-specific decisions.
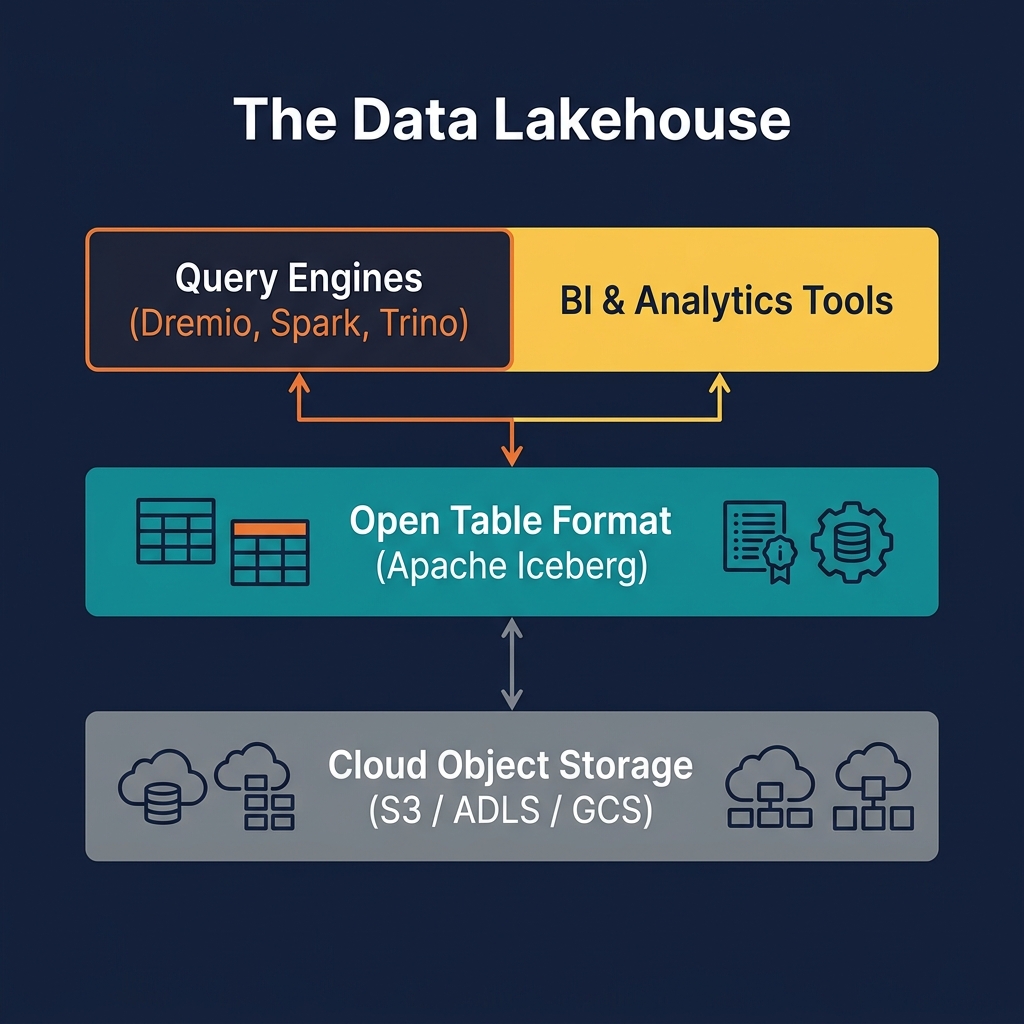
Data Mesh vs. Centralized Data Platform
The contrast between Data Mesh and a centralized data platform is stark:
| Dimension | Centralized Platform | Data Mesh |
|---|---|---|
| Data ownership | Central data team | Domain teams |
| Pipeline development | Central data engineering | Domain engineers |
| Data quality accountability | Central team (bottleneck) | Domain team (owner) |
| Bottleneck | Central team bandwidth | Platform capabilities |
| Schema changes | Require central team coordination | Domain's autonomous decision |
| Discovery | Central catalog | Federated catalog with domain namespaces |
| Governance enforcement | Manual, inconsistent | Automated via platform policies |
| Scale model | Linear with central team size | Scales with number of domain teams |
The Data Mesh model scales with the number of domain teams, not with the size of the central platform team. Adding a new domain to a Data Mesh means onboarding one more team to the platform — not hiring more central data engineers. This is the organizational scalability advantage that makes Data Mesh compelling for large enterprises with dozens of business domains.
Data Products: The Core Unit of Data Mesh
The data product is the fundamental unit of exchange in Data Mesh. A data product is a dataset (or set of related datasets) served by a domain team that meets the following criteria:
- Discoverable: Listed in the platform catalog with human-readable descriptions of its content and intended use cases
- Addressable: Has a stable, versioned URI or identifier that consumers use to access it — the catalog location of the Iceberg table
- Understandable: Has a documented schema, a description of each field, and examples of the data it contains
- Trustworthy: Has published SLAs for freshness (how current is the data?) and availability (what is the uptime?), and the owner is accountable for meeting them
- Interoperable: Accessible by standard query interfaces (SQL, JDBC/ODBC, REST) so that consumers from any domain or tool can use it
- Secure: Access controlled appropriately — some data products are open to all, others require authorization; sensitive data is masked or restricted by the platform's governance layer
In a lakehouse implementation, data products are typically Apache Iceberg tables or collections of related tables, registered in the platform catalog (Apache Polaris or Project Nessie) under a domain namespace. Consumers access data products through the shared query engine (Dremio) without needing to know or manage the underlying storage details.
Implementing Data Mesh on the Lakehouse
Data Mesh and the data lakehouse are complementary architectures that work well together. The lakehouse provides the technical substrate (open storage, open table format, multi-engine access) that makes Data Mesh's organizational principles practically implementable. Here is how each Data Mesh principle maps to lakehouse capabilities:
Domain Ownership → Catalog Namespaces
Each domain team has its own namespace in the Apache Polaris or Nessie catalog. All tables owned by the Sales domain are in the sales.* namespace. Domain teams have admin rights to their own namespace and read rights to approved data products in other namespaces. Storage permissions (S3 bucket/prefix policies) align with catalog namespace boundaries.
Data as a Product → Iceberg Tables with Catalog Metadata
Each domain team's data products are Apache Iceberg tables with schema documentation, quality metrics, and freshness SLAs recorded in the catalog. OpenMetadata or Dremio's Open Catalog provides the data product catalog UI where consumers browse available products across all domains.
Self-Serve Platform → Dremio + Catalog + Ingestion Tools
The central platform team deploys and maintains: the catalog (Polaris), the query engine (Dremio), the ingestion platform (Airbyte, Kafka Connect), the transformation framework (dbt templates), and the monitoring stack. Domain teams consume these as-a-service without managing the infrastructure themselves.
Federated Governance → Policy-as-Code
Global governance policies (column-level PII masking, data retention rules, approved encryption standards) are defined as code and automatically enforced by the platform — through Polaris access control policies and Dremio's column masking rules — across all domains without manual review.
Data Mesh Challenges
Despite its promise, Data Mesh implementations face significant practical challenges:
Organizational Resistance
Data Mesh requires domain teams to accept responsibility for data quality — a responsibility they may not want, especially if they are engineering teams without data expertise. Central data teams may resist losing their monopoly over data pipeline work. Executive sponsorship and cultural change management are prerequisites for successful Data Mesh adoption.
Platform Investment
The self-serve platform must be genuinely easy to use before domain teams will adopt it. A platform that requires domain teams to learn Kubernetes, Terraform, and Iceberg's metadata model before they can publish a data product is not self-serve — it just moves the bottleneck. Building a truly self-serve platform is a significant engineering investment.
Cross-Domain Data Products
Some data products require joining data from multiple domains — a customer 360 view that combines sales, customer support, and marketing data. In Data Mesh, who owns this cross-domain product? The answer is typically a dedicated "integrations" domain or a published data product that joins the inputs from multiple domain namespaces using Dremio's federation and Virtual Dataset capabilities.
Schema Contract Versioning
When a domain team changes the schema of a data product — adding a column, changing a column's type — consumers of that product must be notified and given time to adapt. Establishing a schema versioning and deprecation process is essential but organizationally complex. Apache Iceberg's schema evolution capabilities help by making backward-compatible changes (adding nullable columns) non-breaking for existing consumers.
Data Mesh Governance: Policy as Code
Federated computational governance — the fourth Data Mesh principle — is the mechanism that prevents decentralized ownership from producing governance chaos. The key insight is that governance policies should be automated and enforced by the platform, not enforced through manual review processes.
Policy as Code
Governance policies are defined as code — YAML, JSON, or a domain-specific language — and version-controlled in a Git repository. When a domain team publishes a new data product, the platform automatically validates it against all applicable policies and refuses to register it if violations are found.
Examples of platform-enforced policies:
- Any column with a name matching PII patterns (email, ssn, phone) must have a masking policy applied
- All tables in the
*.rawnamespace must have a retention policy of no more than 90 days - All data products must have a designated owner recorded in catalog metadata
- All tables containing PII must be encrypted with domain-specific KMS keys
Dremio's Role in Federated Governance
Dremio enforces federated governance at the query engine level: role-based access control policies determine which users and services can access which domain namespaces. Column-level masking policies automatically mask PII fields for users without the appropriate privilege, regardless of which table they are querying. These policies are applied consistently across all queries, whether from BI tools, dbt transformations, or AI agents.
Data Mesh and Agentic AI
Data Mesh is particularly well-suited to the emerging agentic AI paradigm, where AI agents autonomously discover, query, and reason over enterprise data to complete complex analytical tasks.
In a Data Mesh, each domain's data products are clearly cataloged with human-readable descriptions — making them discoverable by AI agents using catalog search APIs. The catalog's schema metadata, column descriptions, and sample data give AI agents the context they need to formulate correct queries without human intervention.
The Model Context Protocol (MCP) is emerging as the standard interface for AI agents to interact with data catalogs and query engines. Dremio's MCP server exposes the lakehouse's data products — domain namespaces, table schemas, column descriptions — to AI agents, enabling them to autonomously explore and query data products across all domains. The Data Mesh's clear data product ownership model provides the governance guardrails: each agent's access is scoped to the domains and tables it has been authorized to use.
Is Data Mesh Right for Your Organization?
Data Mesh is not appropriate for every organization. It requires a specific organizational context to deliver its benefits:
Data Mesh Is a Good Fit When
- Your organization has multiple distinct business domains (Sales, Marketing, Logistics, Finance, Customer Support) with different data models and ownership
- Your central data team is a bottleneck — domain teams wait weeks for pipeline changes or new data products
- You have more than ~50 data producers or ~10 distinct data domains
- Domain teams have sufficient engineering capability to own and maintain data pipelines
- You have strong executive sponsorship for organizational change
Data Mesh Is NOT a Good Fit When
- Your organization is small (fewer than 100 people in total)
- You have a single business domain or tightly integrated data model
- Domain teams lack the technical capability to build and maintain data products
- You are in an early stage of data maturity — building your first centralized platform first is the right choice
For organizations that do not need full Data Mesh, a well-organized centralized data lakehouse with clear data domain ownership conventions (well-named namespaces, documented tables, quality metrics) can provide many of Data Mesh's benefits without the full organizational transformation.
Summary
Data Mesh is the most significant paradigm shift in enterprise data organization since the data warehouse. By applying domain-driven design principles to data — decentralizing ownership to domain teams, treating data as products, providing self-serve infrastructure, and automating governance — it addresses the organizational scalability failures that plague large centralized data platforms.
The data lakehouse is the ideal technical substrate for Data Mesh: Apache Iceberg's multi-engine, open storage model enables domain teams to use their preferred compute tools while sharing a common catalog. Apache Polaris and Project Nessie provide namespaced, federated catalog management. Dremio provides the self-serve query engine that domain teams and consumers use to build and consume data products. And Dremio's federated governance capabilities enforce the global policies that keep a decentralized mesh coherent.
For organizations ready to make the organizational investment, Data Mesh on a lakehouse substrate represents the state of the art in scalable, domain-driven, AI-ready enterprise data architecture.