What Is Schema Evolution?
Schema evolution is the ability to change a table's column definitions over time as business requirements change — adding new fields, dropping obsolete ones, renaming columns to align with updated terminology, or widening numeric types to accommodate larger values.
Without schema evolution support, every structural change to a table requires a complete data rewrite: reading all existing data and writing it in the new format. At petabyte scale, this is prohibitively expensive and introduces hours of pipeline downtime. Apache Iceberg's schema evolution model eliminates this cost entirely — schema changes are metadata-only operations that complete in milliseconds regardless of table size.
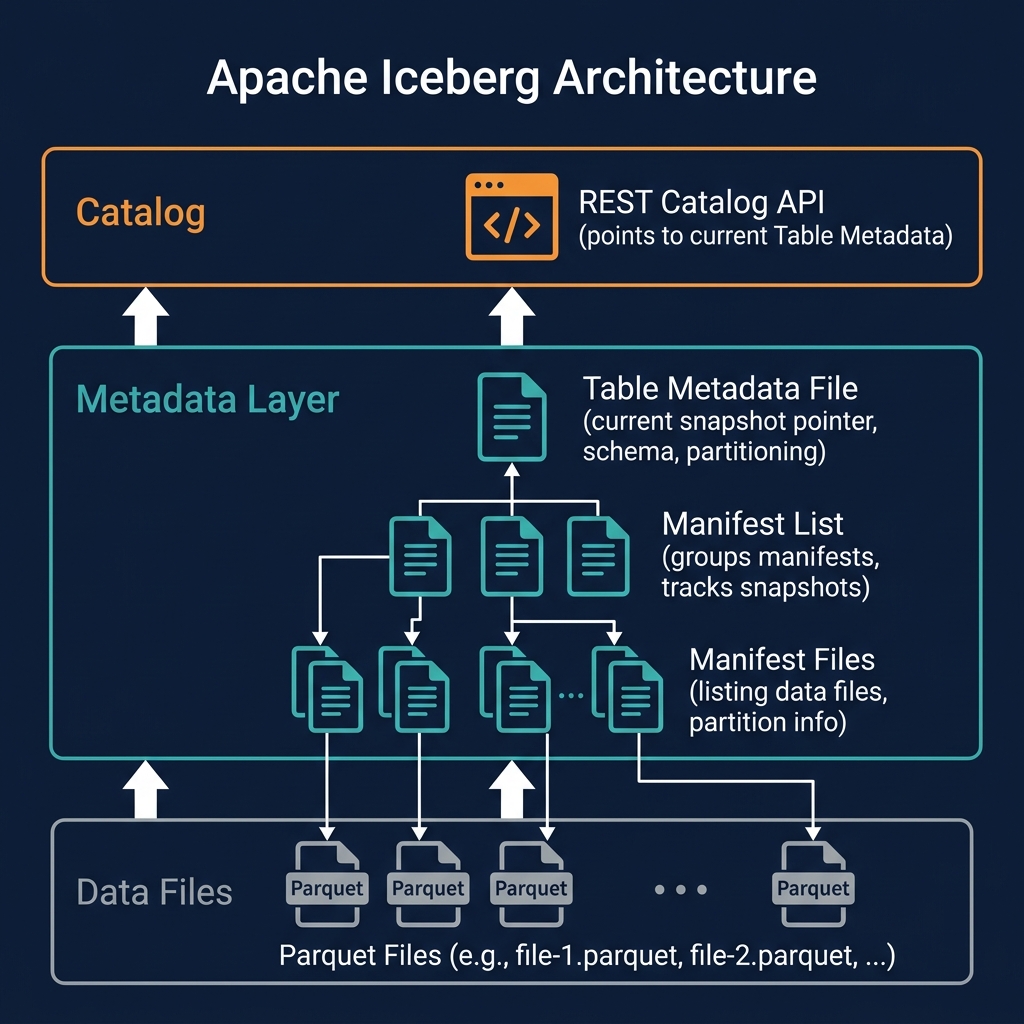
The foundation of Iceberg's schema evolution is column IDs: each column is assigned a unique, stable integer ID when first created. This ID never changes — not when the column is renamed, not when it is reordered. Data files store column data alongside these IDs. When a query engine reads an old file after a schema change, it matches columns by ID, not name, correctly interpreting data even if column names or positions have changed.
This makes Iceberg schema evolution genuinely safe: renaming a column in an Iceberg table does not risk misinterpreting old data as new column data — a failure mode common in simpler Hive-style name-based column tracking.
Safe Schema Changes
Apache Iceberg supports the following backward-compatible schema changes without data rewrites:
Add Column
Adding a new nullable column. Old data files return null (or a specified default) for the new column. New files write the actual values. Executed with: ALTER TABLE tbl ADD COLUMN col_name data_type.
Drop Column
Removing a column from the schema. The column's ID is retired — data remains in old files but is invisible to queries. No rewrite needed. Storage is reclaimed only when old files are replaced during compaction.
Rename Column
Changing a column's name. The ID is unchanged; old files continue to work. Queries must use the new name after renaming. Executed with: ALTER TABLE tbl ALTER COLUMN old_name RENAME TO new_name.
Reorder Columns
Changing the display order of columns in the schema. The engine uses IDs to read columns from files regardless of order in the schema definition.
Widen Column Type
Expanding a numeric type — INT to LONG, FLOAT to DOUBLE — is safe because all existing values fit in the wider type. Type narrowing (LONG to INT) is rejected because it risks data loss.
Breaking Schema Changes
Some schema changes are not backward-compatible and are rejected by Iceberg:
Type Narrowing
Changing LONG to INT is rejected because existing long values may exceed int range. The correct approach: add a new column with the narrower type and backfill it from the old column.
Changing Nullability to NOT NULL
Existing data files may contain null values. Iceberg cannot retroactively enforce NOT NULL on historical files without a rewrite.
Partition Column Changes
Changing partition expressions requires partition evolution, which is a separate Iceberg operation with its own semantics — not a schema change.
Schema Evolution in the Medallion Architecture
Schema evolution is most frequently needed at the Bronze layer, where source system changes propagate into the lakehouse. When a production database adds a new column, the Bronze Iceberg table can be updated with a simple ALTER TABLE statement — no pipeline downtime, no data rewrite.
For example, when a CRM system adds a customer_segment field, the data engineer runs: ALTER TABLE bronze.customers ADD COLUMN customer_segment STRING. Historical Bronze records return null for this column; new records include the value. The Silver transformation handles the null for historical rows, and the Gold aggregation can conditionally include or exclude the new field.
This graceful handling of source schema changes is one of the most practical day-to-day benefits of Iceberg over the Hive Metastore model, where a new source column often required a full table recreation with a blocking pipeline downtime window.
Schema Evolution in Dremio
Dremio exposes Iceberg schema evolution through standard SQL DDL statements executed against any Iceberg table in the catalog:
ALTER TABLE tbl ADD COLUMN col STRINGALTER TABLE tbl DROP COLUMN colALTER TABLE tbl ALTER COLUMN old RENAME TO newALTER TABLE tbl ALTER COLUMN col TYPE BIGINT
All operations are metadata-only and ACID-compliant — committed as new Iceberg snapshots. Other engines connected to the same catalog see the schema change immediately after the commit, without any cache invalidation required. Dremio's query planner correctly handles mixed-schema files — reading null for new columns from old files and actual values from new files — transparently.
Schema Evolution with dbt
dbt supports Iceberg schema evolution through its on_schema_change configuration on incremental models:
ignore: Do not modify the target table when schema changesfail: Fail the run on schema changes — for environments requiring reviewappend_new_columns: Add new columns to the Iceberg target using ADD COLUMN (recommended for most cases)sync_all_columns: Add new and drop removed columns on each run
append_new_columns is the recommended production setting. When a dbt model's SELECT adds a new column, dbt issues a single ALTER TABLE ADD COLUMN DDL statement against the Iceberg table — triggering a metadata-only schema evolution — then runs the incremental query to populate the new column for new records only. Historical records return null for the new column, consistent with Iceberg's backward-compatible add column semantics.
Multi-Engine Schema Evolution
One of Iceberg's key advantages is that schema evolution is consistent across all engines. When Dremio renames a column, Spark, Trino, and Flink immediately see the rename through the catalog. No engine-specific cache invalidation or configuration change is required.
This is because all engines share the same catalog and read the same table metadata file. The catalog serves as the single source of truth for the current schema. All engines read the current schema version from the metadata before planning queries — ensuring that after a schema change, every subsequent query from any engine sees the new schema.
Compare this to schema management in the Hive Metastore, where each engine might cache schema definitions locally and cache invalidation across multiple engines required manual coordination. Iceberg's centralized, catalog-driven schema management is a significant operational simplification for multi-engine lakehouse deployments.
Nested Type Schema Evolution
Schema evolution in Apache Iceberg applies not just to top-level columns but also to nested types: structs, maps, and lists. This capability is important for tables that store semi-structured data as nested columns.
Struct Evolution
Columns with struct types can have their sub-fields added, dropped, or renamed using the same column ID mechanism. Sub-fields within a struct are also assigned unique IDs. This means a deeply nested struct field can be renamed without any data rewrite.
Map Evolution
The value type of a map column can be widened. Adding fields to a map value struct follows the same rules as top-level struct evolution.
List Evolution
The element type of a list column can be widened. For lists of structs, the struct's fields can be evolved following struct evolution rules.
Nested type evolution is particularly valuable for tables ingesting JSON or Avro data with deeply nested schemas — a common pattern in event-driven architectures where event payloads evolve frequently.
Schema Evolution Best Practices
Managing schema evolution in production requires both technical correctness and organizational process:
- Never reference columns by position. Always use column names (which map to stable IDs) in queries and application code. Positional column references break when columns are reordered.
- Communicate renames in advance. A column rename is a breaking change for existing queries referencing the old name. Provide 30 days notice to downstream query owners, or use a dual-column transition (add new, deprecate old, then drop old).
- Keep a schema change log. Document every schema change with the date, justification, and approver. This log is essential for debugging historical data issues.
- Test schema changes on a branch. Use Nessie branches to apply schema changes to a staging branch and validate downstream pipelines before promoting to the main production branch.
- Prefer adding over modifying. Adding a new column is always safer than modifying an existing one. When business logic changes how a field should be computed, add a new column rather than changing the semantics of the existing one.
Summary
Schema evolution is one of Apache Iceberg's most practically valuable features. By tracking columns with stable integer IDs and implementing schema changes as metadata-only operations, Iceberg allows data teams to evolve their schemas freely — in response to source system changes, business requirement updates, or organizational terminology shifts — without the operational disruption and cost of data file rewrites.
The combination of schema evolution, partition evolution, and time travel makes the data lakehouse a genuinely adaptive platform that can evolve with real-world data engineering needs. Dremio's SQL DDL interface makes schema evolution accessible to any data practitioner without requiring Spark or deep Iceberg expertise.