What Is the Iceberg REST Catalog?
The Iceberg REST Catalog (officially the Apache Iceberg REST Catalog API) is an open HTTP API specification published by the Apache Iceberg project that defines the standard interface between query engines and catalog services. It specifies the exact HTTP endpoints, request/response schemas, and authentication flows that catalog implementations must provide and that query engine clients must consume.
Before the REST catalog specification, each query engine had its own catalog integration layer: Spark used the HiveCatalog or its own SparkCatalog, Trino used its own MetaStore connector, Presto had its own implementations. Connecting a new engine to a new catalog required writing and maintaining an engine-specific catalog plugin — a significant engineering burden that slowed ecosystem growth and created fragmentation.
The REST catalog eliminates this fragmentation. Any engine that implements the REST catalog client can connect to any catalog that implements the REST catalog server — with no engine-specific plugins required. The catalog API becomes a commodity interface, and competition shifts from catalog protocols to catalog features (governance, performance, durability, multi-tenancy).
REST Catalog API Endpoints
The Iceberg REST Catalog specification defines endpoints across three functional areas:
Namespace Management
GET /v1/namespaces— list all namespaces (schemas)POST /v1/namespaces— create a new namespaceGET /v1/namespaces/{namespace}— get namespace metadataDELETE /v1/namespaces/{namespace}— drop a namespace
Table Management
GET /v1/namespaces/{namespace}/tables— list tables in a namespacePOST /v1/namespaces/{namespace}/tables— create a tableGET /v1/namespaces/{namespace}/tables/{table}— load table metadata (returns current metadata file location)DELETE /v1/namespaces/{namespace}/tables/{table}— drop a tablePOST /v1/namespaces/{namespace}/tables/{table}/rename— rename a table
Transaction Commits
POST /v1/namespaces/{namespace}/tables/{table}/metrics— report query metricsPOST /v1/transactions/commit— atomic multi-table transaction commit
The load table endpoint is the most critical: it returns the current metadata file location and storage credentials for the table, which the engine uses to read the complete Iceberg metadata tree and then access the actual data files.
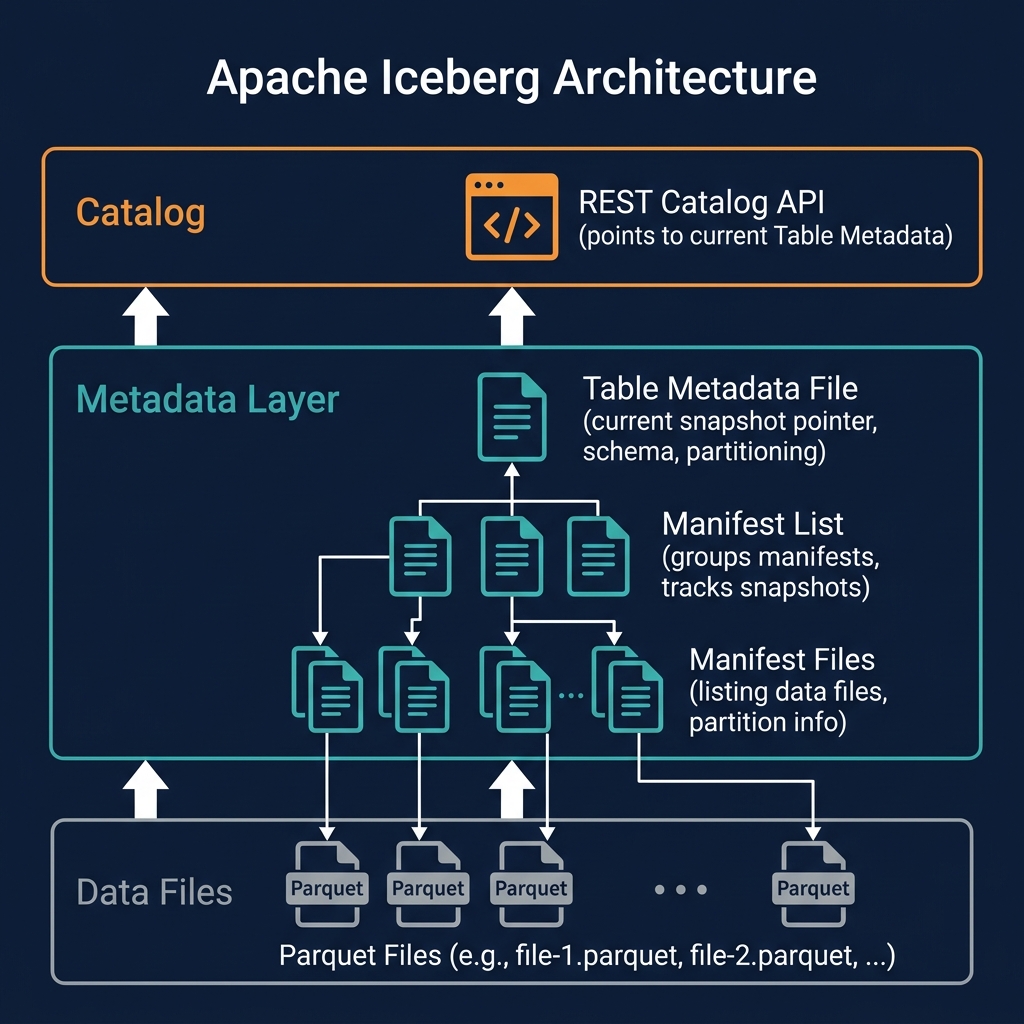
Authentication and Authorization
The Iceberg REST Catalog specification includes an OAuth2-based authentication flow. Clients obtain bearer tokens from the catalog's token endpoint and include them in all subsequent API requests. The catalog authenticates the token and enforces authorization policies — determining which namespaces and tables the authenticated identity can access.
This standardized auth model enables fine-grained, catalog-enforced access control: only principals with the appropriate grants can create tables, load metadata, or commit transactions against specific namespaces. The security model is enforced at the catalog API layer — not in the query engine — ensuring consistent enforcement regardless of which engine is connecting.
Major REST Catalog Implementations
The REST catalog spec has attracted implementations from across the ecosystem:
Apache Polaris
Donated to the Apache Software Foundation by Snowflake in 2024, Apache Polaris is the community-governed reference implementation of the REST catalog spec. It provides namespace management, table registration, RBAC access control, and credential vending for S3/ADLS/GCS. Polaris is the primary catalog for organizations seeking a fully open, vendor-neutral catalog.
Project Nessie
Project Nessie, developed by Dremio, extends the REST catalog spec with Git-like branching and tagging semantics. It powers Dremio's Open Catalog and enables advanced data engineering workflows: isolated branches for experimentation, tagged releases for reproducible ML training, and atomic cross-table commits via branches.
AWS Glue
AWS Glue Data Catalog now exposes a REST catalog API, making it a drop-in catalog for any Iceberg-compatible engine running on AWS. Glue's catalog is serverless and integrates natively with S3, IAM, Lake Formation, and Athena.
Credential Vending
A critical feature of the REST catalog that distinguishes it from the Hive Metastore model is credential vending: the catalog returns temporary, short-lived cloud storage credentials alongside table metadata when an engine loads a table. These credentials scope the engine's storage access to only the files needed for the requested operation.
Without credential vending, engines need broad, long-lived storage credentials to access all data in the lake — a significant security risk. With vended credentials, the catalog can enforce fine-grained, per-request storage access control: engines get temporary S3 credentials scoped to the specific S3 prefix of the table they requested, expiring after a short window. This makes the REST catalog a security enforcement point, not just a metadata directory.
REST Catalog and Multi-Engine Lakehouses
The REST catalog specification is the technical foundation of the multi-engine lakehouse. When Dremio, Apache Spark, Trino, and Apache Flink all connect to the same REST catalog (e.g., Apache Polaris), they share a single metadata namespace: table schemas, partition specs, snapshot history, and access control policies are defined once and enforced consistently across all engines. A table created by Spark is immediately queryable by Dremio; a schema change committed by Dremio is immediately visible to Trino — all through the shared REST catalog.
Summary
The Iceberg REST Catalog specification is the catalog interoperability standard for the open lakehouse ecosystem. By defining a common HTTP API for catalog operations, it eliminates engine-specific catalog integrations, creates plug-and-play interoperability between catalog implementations and query engines, and enables fine-grained security through credential vending. Together with Apache Iceberg's table format specification, the REST Catalog spec forms the two-layer standard that makes the truly open, multi-engine data lakehouse a reality.