What Are Row-Level Deletes?
Row-level deletes in Apache Iceberg are the capability to remove specific rows from a table without rewriting entire data files. Introduced in the Iceberg V2 specification, row-level deletes use delete files — auxiliary Avro files that identify rows to be excluded from query results — to implement DELETE and UPDATE operations with minimal write amplification.
Before Iceberg V2 (and in Copy-on-Write mode), deleting rows required reading the entire affected partition file and rewriting it without the deleted rows — expensive for large files with few deletions. With V2 delete files, a DELETE that removes 100 rows from a 500MB file requires writing only a tiny delete file (a few kilobytes) rather than rewriting 500MB of data. The actual data file remains unchanged; the delete file tells the query engine which rows to exclude at read time.
Row-level deletes are essential for several critical data engineering use cases: GDPR and CCPA right-to-erasure, CDC upsert pipelines, SCD type 2 (Slowly Changing Dimensions) implementations, and data correction workflows where specific erroneous records must be removed.
Positional Delete Files
Positional delete files are Avro files where each record specifies the exact location of a deleted row: a file path (the S3 URL of the data file containing the deleted row) and a row position offset (the zero-indexed row number within that file).
When a query engine reads a data file, it checks for associated positional delete files. For each row read, it checks whether that row's file path + position appears in any delete file. If it does, the row is skipped. If not, the row is included in the result.
Positional deletes are created by the query engine during UPDATE and DELETE operations when the Merge-on-Read write mode is active. Because they identify rows by physical position in a specific file, they are tightly coupled to the current data file layout — if the data file is rewritten (by compaction), the positional delete file becomes stale and must be discarded (or the compaction must apply the deletes as part of the rewrite).
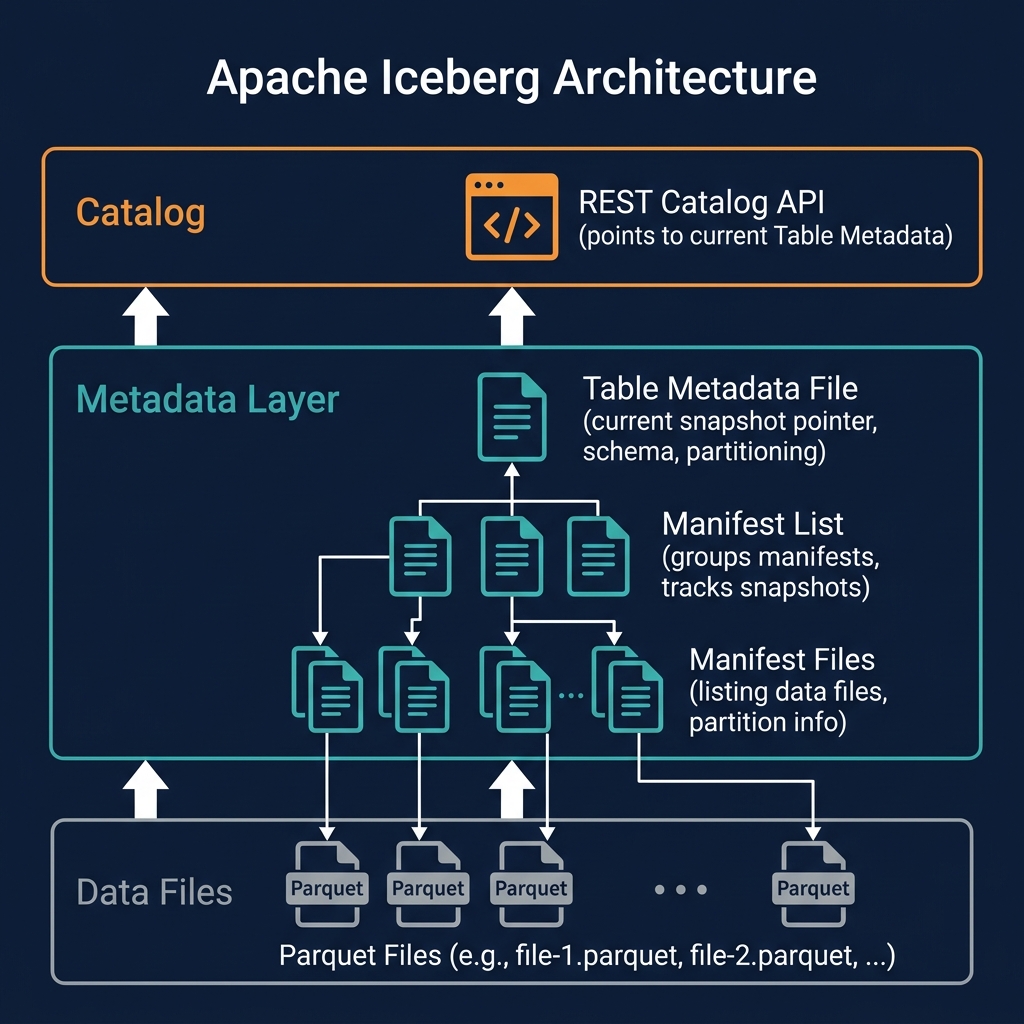
Equality Delete Files
Equality delete files are Avro files where each record specifies column values that identify rows to delete. For example, an equality delete file for a customer GDPR erasure might contain: {customer_id: 'abc123'}. Any row in any data file where customer_id = 'abc123' is excluded from query results.
Equality deletes are more flexible than positional deletes because they are not tied to the physical file layout — they work correctly even if data files are rewritten by compaction. However, evaluating equality deletes requires comparing each queried row's column values against the delete file's predicates, which is more computationally expensive than checking a position index.
Equality deletes are the natural mechanism for CDC MERGE INTO operations: when a source system deletes a customer record, the CDC event carries the customer's primary key. An equality delete file records this key, and all historical appearances of that customer record across all data files are immediately excluded from queries.
GDPR Right-to-Erasure with Iceberg Row-Level Deletes
GDPR Article 17 requires the ability to erase all data relating to an individual upon their request. In a traditional data lake without row-level deletes, GDPR erasure requires identifying every file containing the customer's data and rewriting each one without their records — a full-table scan and rewrite operation that can take hours for large tables.
With Iceberg V2 equality delete files, GDPR erasure is a two-step process:
- Logical deletion (immediate): Write an equality delete file specifying
{customer_id: 'erased_customer_id'}. From this moment, no query against the table will return any records for that customer — the equality delete applies across all historical data files instantaneously. - Physical deletion (scheduled): Over the next retention window, scheduled compaction rewrites all data files, applying the equality delete and physically removing the customer's rows from the Parquet files. After snapshot expiration and orphan file cleanup, no physical trace of the customer's data remains in storage.
This two-phase approach allows immediate GDPR compliance (query-visible deletion) while deferring the expensive physical rewrite to a scheduled background process.
Row-Level Deletes in CDC Pipelines
Row-level deletes are the foundation of CDC upsert pipelines in the Iceberg lakehouse. A MERGE INTO operation — the SQL expression of a CDC upsert — produces different write operations depending on the match condition:
- WHEN MATCHED THEN UPDATE: Writes an equality delete file for the matched rows (removing the old version) + a new data file with the updated row (inserting the new version)
- WHEN MATCHED THEN DELETE: Writes an equality delete file for the matched rows
- WHEN NOT MATCHED THEN INSERT: Writes a new data file with the inserted row (no delete file needed)
The combination of equality delete files (removing old versions) and new data file appends (adding new versions) provides the full MERGE INTO semantics with minimal write amplification. For Dremio, MERGE INTO against Iceberg tables in MoR mode is the standard pattern for CDC Silver layer implementations.
Managing Delete File Accumulation
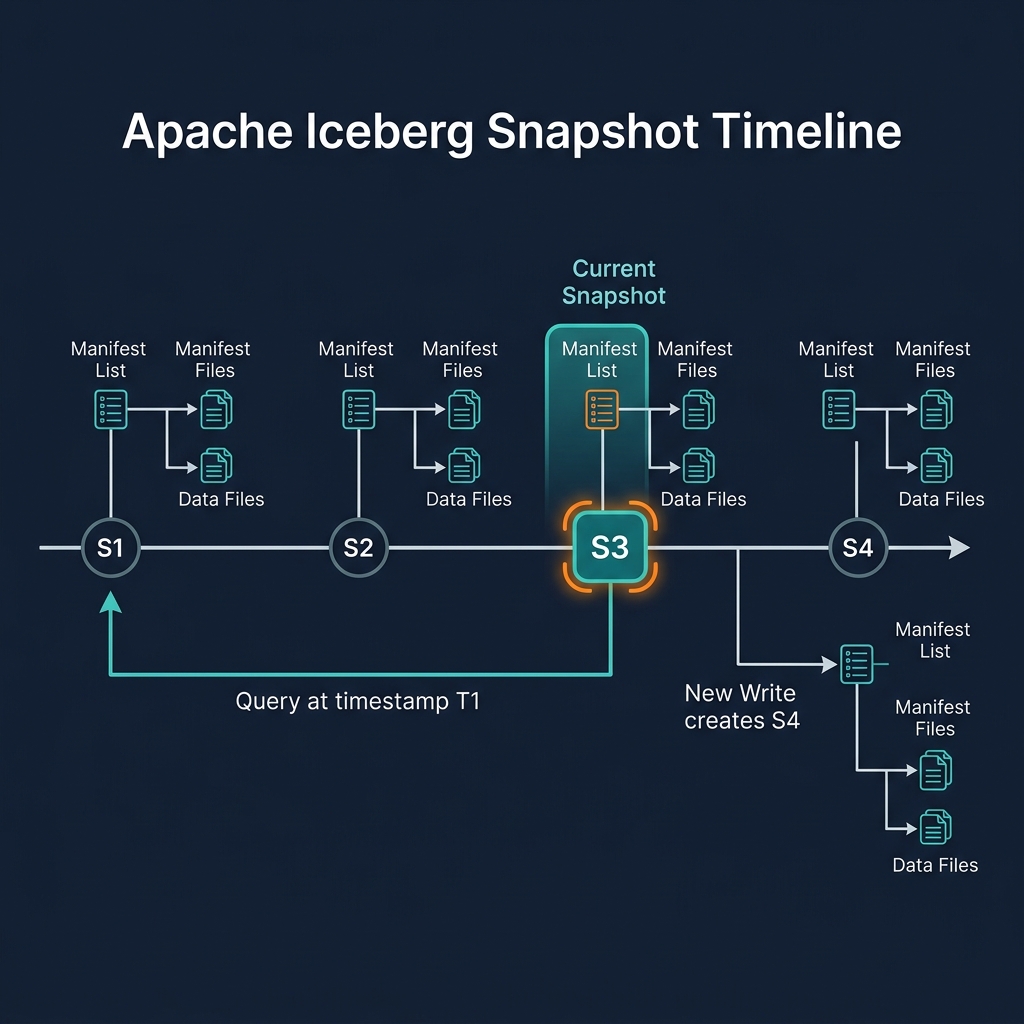
Delete files accumulate over time as UPDATE and DELETE operations are performed. Query performance degrades as more delete files must be merged at read time. Three maintenance operations manage delete file accumulation:
- Data file compaction (MoR to CoW): Reads data files and their associated delete files, applies all deletes, and writes new clean data files without any delete files. After compaction, queries no longer need to apply delete files for the compacted partition.
- Snapshot expiration: After compaction, old snapshots referencing the pre-compaction data files + delete files can be expired. This releases the delete files for garbage collection.
- Orphan file cleanup: After snapshot expiration, the original data files (pre-compaction) and their delete files are removed from storage.
Dremio's automated table optimization handles all three operations, maintaining optimal read performance without manual intervention.
Summary
Row-level deletes are one of the most important practical capabilities in Apache Iceberg V2. By writing small delete files instead of rewriting entire data files, they make GDPR erasure, CDC upserts, and data correction workflows practical at lakehouse scale — operations that were prohibitively expensive in the data lake era. Understanding positional vs equality delete files, and managing delete file accumulation through scheduled compaction, is fundamental to operating a production Iceberg lakehouse with frequent DML operations.