What Is Column Pruning?
Column pruning (also called column projection pushdown) is the query optimization technique of reading only the columns that a SQL query actually needs from the underlying data files, rather than reading all columns for every row. It is the columnar storage equivalent of predicate pushdown: where predicate pushdown eliminates rows, column pruning eliminates columns.
Column pruning is particularly powerful in wide table scenarios common in the lakehouse: a table with 200 columns storing all customer attributes, behavioral signals, and computed features. A dashboard query that needs only 5 of those columns — name, email, segment, LTV, last_purchase_date — can read roughly 2.5% of the total data by reading only those 5 column chunks. The other 195 column chunks are never fetched from object storage.
This optimization is only possible because of the columnar storage format of Apache Parquet and Apache ORC: each column's data is stored contiguously and independently, with byte offsets in the file footer that allow direct seeks. In a row-oriented format (like CSV or traditional OLTP storage), column pruning is impossible without reading and discarding the unwanted column values for each row.
How Column Pruning Works with Apache Parquet
Apache Parquet's physical layout enables column pruning at the byte level:
- The query engine reads the Parquet file footer, which contains the column schema and the byte offset and size of each column chunk within each row group
- The query planner identifies which columns are needed (from SELECT, WHERE, GROUP BY, JOIN ON clauses)
- The storage reader seeks directly to the byte offsets of only the needed column chunks, reading only those bytes from S3 or ADLS
- For columns that are not needed, zero bytes are read from storage — not just filtered in memory, but never fetched at all
The combination of column pruning (read fewer columns) and predicate pushdown (read fewer rows) is what makes analytical queries on wide, large Parquet tables practical at sub-second latency.
Column Pruning and the Medallion Architecture
Column pruning is especially impactful at the Gold layer of the Medallion Architecture, where wide tables often store dozens or hundreds of pre-computed attributes. Common Gold table patterns:
- Customer 360 table: 150+ columns covering demographics, behavior, segments, scores. Most queries need 5–10 columns. Column pruning reads 3–7% of the data.
- Product attributes table: 200 columns covering all product metadata. A price analysis query reads only 3 columns. Column pruning reads 1.5% of the data.
- Event fact table: 50 columns capturing all event attributes. An engagement funnel query reads 8 columns. Column pruning reads 16% of the data.
In each case, column pruning transforms what would be a full-width table scan into a narrow column read — the difference between seconds and milliseconds for interactive BI queries.
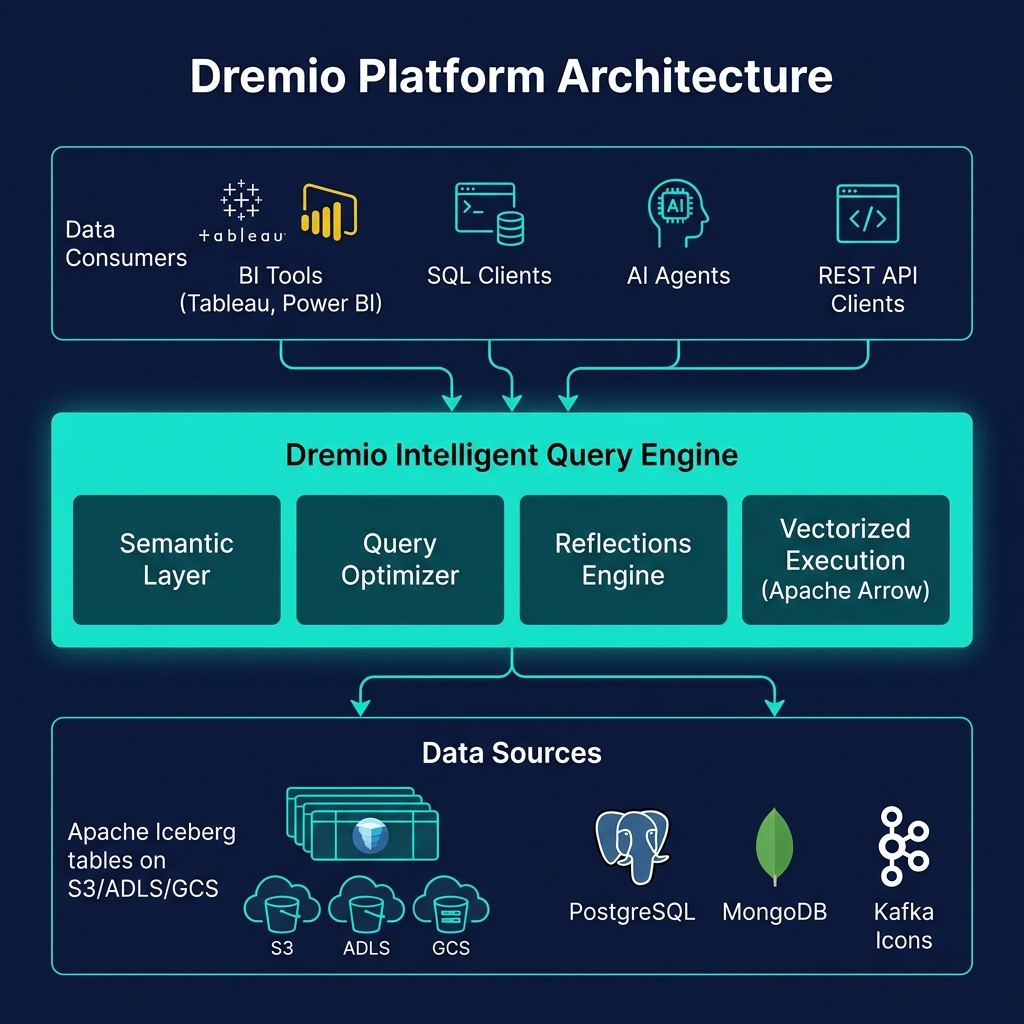
Column Pruning in Dremio
Dremio implements column pruning at multiple levels of its query pipeline:
- Logical planning: The Dremio planner analyzes the query's column references across all SQL clauses (SELECT, WHERE, JOIN, GROUP BY, HAVING, ORDER BY) and produces a minimal column set
- Physical planning: Column projections are pushed into the Iceberg scan operator, which passes them to the Parquet reader
- Parquet reader: Only the specified column chunks are fetched from S3/ADLS, with byte-level precision using Parquet footer offsets
- Arrow execution: Data enters Dremio's vectorized pipeline as Arrow RecordBatches containing only the needed columns — subsequent operators never see or allocate memory for pruned columns
Summary
Column pruning is a foundational query optimization that works automatically in every modern data lakehouse engine. By reading only the columns a SQL query needs from Apache Parquet files, it eliminates the vast majority of storage I/O for wide-table queries — the common pattern in Gold layer analytics. Together with predicate pushdown (eliminating rows), column pruning and predicate pushdown are the two most impactful query optimizations for large-scale analytical workloads, and choosing columnar file formats like Parquet is what makes both optimizations possible.