What Is Vectorized Query Execution?
Vectorized query execution is a query engine architecture that processes data in column-oriented batches (called vectors) rather than handling one complete row at a time. Instead of fetching all column values for row 1, processing them, then moving to row 2, a vectorized engine fetches all values for column A for rows 1–1024, processes the entire batch with a single SIMD CPU operation, then moves to column B for the same batch of rows.
This approach aligns with how modern CPUs work most efficiently: SIMD (Single Instruction, Multiple Data) instructions in SSE, AVX2, and AVX-512 instruction sets can apply a single arithmetic or comparison operation to 4, 8, 16, or 32 numeric values simultaneously. By processing data in column-oriented batches, vectorized engines keep the CPU's execution units saturated with useful work and minimize the instruction dispatch overhead that dominates row-at-a-time processing.
The result is analytical query performance that is 10–100x faster than traditional row-at-a-time SQL engines — the key performance advantage that makes Dremio, DuckDB, Snowflake, and other modern analytical engines competitive for sub-second BI queries on large datasets.
Vectorized vs. Row-at-a-Time Execution
To understand why vectorized execution is so much faster, consider a simple sum aggregation: SELECT SUM(revenue) FROM orders.
Row-at-a-Time Execution (Volcano Model)
The traditional Volcano model: for each row, call next() to fetch the row, extract the revenue column, add to accumulator, repeat. Per-row overhead: function call overhead, type dispatch, branch mispredictions, cache misses (row data is not contiguous in memory). For 1 billion rows, this means 1 billion function calls.
Vectorized Execution
Fetch a batch of 1024 revenue values as a contiguous double[] array. Apply AVX2 vectorized sum to 4 doubles simultaneously: 256 AVX operations for 1024 values. Repeat for the next 1024 values. For 1 billion rows: ~976,563 vectorized batch operations. CPU cache is warm (data is contiguous); SIMD units are fully utilized; branch prediction is perfect (no type dispatch).
The throughput difference can be 10–50x for simple aggregations and even larger for complex multi-column operations.
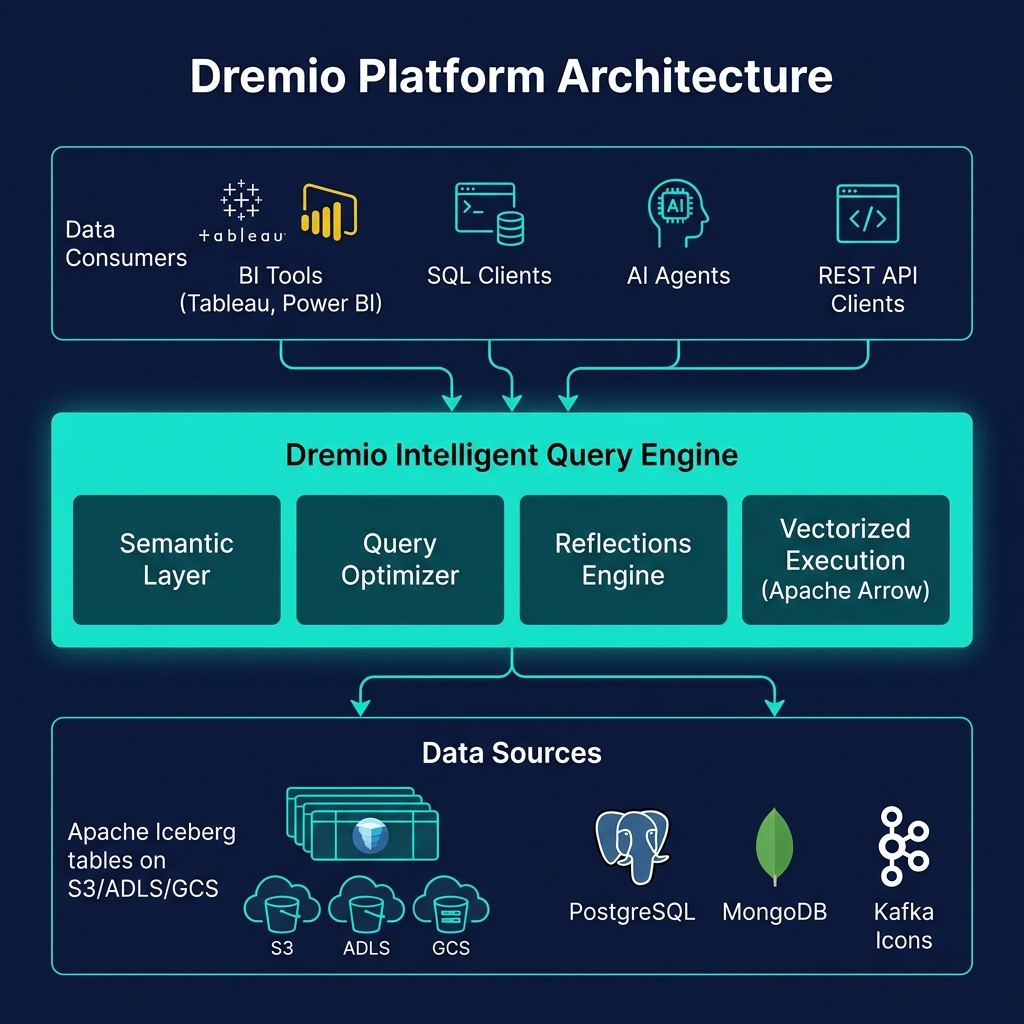
Apache Arrow: The Vectorized Execution Standard
Apache Arrow defines the in-memory columnar format standard used by vectorized engines. An Arrow RecordBatch is a fixed-size batch of column buffers — contiguous memory arrays of typed values (int64[], double[], utf8 string buffers) with null bitmaps. Arrow's format is designed specifically for vectorized processing: column buffers are cache-aligned, SIMD-accessible, and zero-copy shareable between processes and engines.
When Dremio uses Apache Arrow as its internal execution format, data moves between query stages (scan, filter, aggregate, join) without any serialization — each stage receives Arrow RecordBatches and returns Arrow RecordBatches. SIMD operations apply directly to the Arrow buffer memory. The Arrow Flight SQL protocol transmits results between Dremio and clients also in Arrow format — zero-copy for Python clients using PyArrow.
Vectorized Execution in the Lakehouse Stack
Vectorized execution interacts with the lakehouse stack at multiple levels:
Parquet Column Chunk Decoding
Apache Parquet stores data in column chunks with RLE/Dictionary encoding. Vectorized decoders read entire column chunks at once, applying batch decoding that feeds directly into Arrow column buffers — enabling a continuous vectorized pipeline from storage bytes to query result.
Predicate Evaluation
Row-level filter predicates (WHERE revenue > 1000) are evaluated on entire column batches using vectorized comparisons, producing bit vectors that identify rows to keep. These bit vectors are then applied to all other column batches simultaneously — no per-row branching.
SIMD-Optimized Hash Aggregation
Hash GROUP BY operations use SIMD-optimized hash tables that process multiple rows simultaneously, dramatically accelerating the most common analytical query pattern.
Summary
Vectorized query execution is the performance foundation of every modern analytical engine — including Dremio, Snowflake, BigQuery, DuckDB, and Spark's Tungsten engine. By aligning data processing with CPU SIMD capabilities through column-oriented batch operations, vectorized engines achieve 10–100x throughput improvements over traditional row-at-a-time SQL execution. In the data lakehouse, vectorized execution built on Apache Arrow is what makes sub-second BI queries on petabyte-scale Iceberg tables possible — the engine-level technology that powers every Reflection response, every dashboard refresh, and every AI agent data query.