What Is Copy-on-Write?
Copy-on-Write (CoW) is the write strategy in Apache Iceberg where UPDATE and DELETE operations produce clean, complete data files by rewriting the affected source files with the changes applied. When a DELETE removes rows from a data file, CoW reads the entire source file, filters out the deleted rows, and writes a new file containing only the surviving rows. When an UPDATE modifies rows, CoW reads the source file, applies the updates, and writes a new file with the updated values.
The key property of CoW is that the resulting data files contain no delete markers, no separate delete files, and no rows that need to be filtered — they are clean, complete Parquet files. Reading a CoW table never requires merging separate data and delete files. This makes reads fast, with no merge overhead at query time.
The trade-off is write amplification: even a UPDATE that modifies one row in a 500MB file requires reading and rewriting the entire 500MB file. For tables with frequent small updates, this write amplification makes CoW prohibitively expensive.
CoW vs Merge-on-Read
The choice between CoW and Merge-on-Read (MoR) is fundamentally a read/write trade-off:
| Dimension | Copy-on-Write | Merge-on-Read |
|---|---|---|
| Write cost | High (rewrites affected files) | Low (writes small delete files) |
| Read cost | Low (clean files, no merge) | Higher (merges delete files at read) |
| Concurrency | Good | Excellent (minimal write overhead) |
| Best for | Infrequent updates, BI workloads | Frequent updates, CDC streaming |
| Compaction needed | For small file merging only | Required (delete file compaction) |
Most production tables use CoW for the Gold layer (where reads dominate) and MoR for Silver (where CDC updates are frequent).
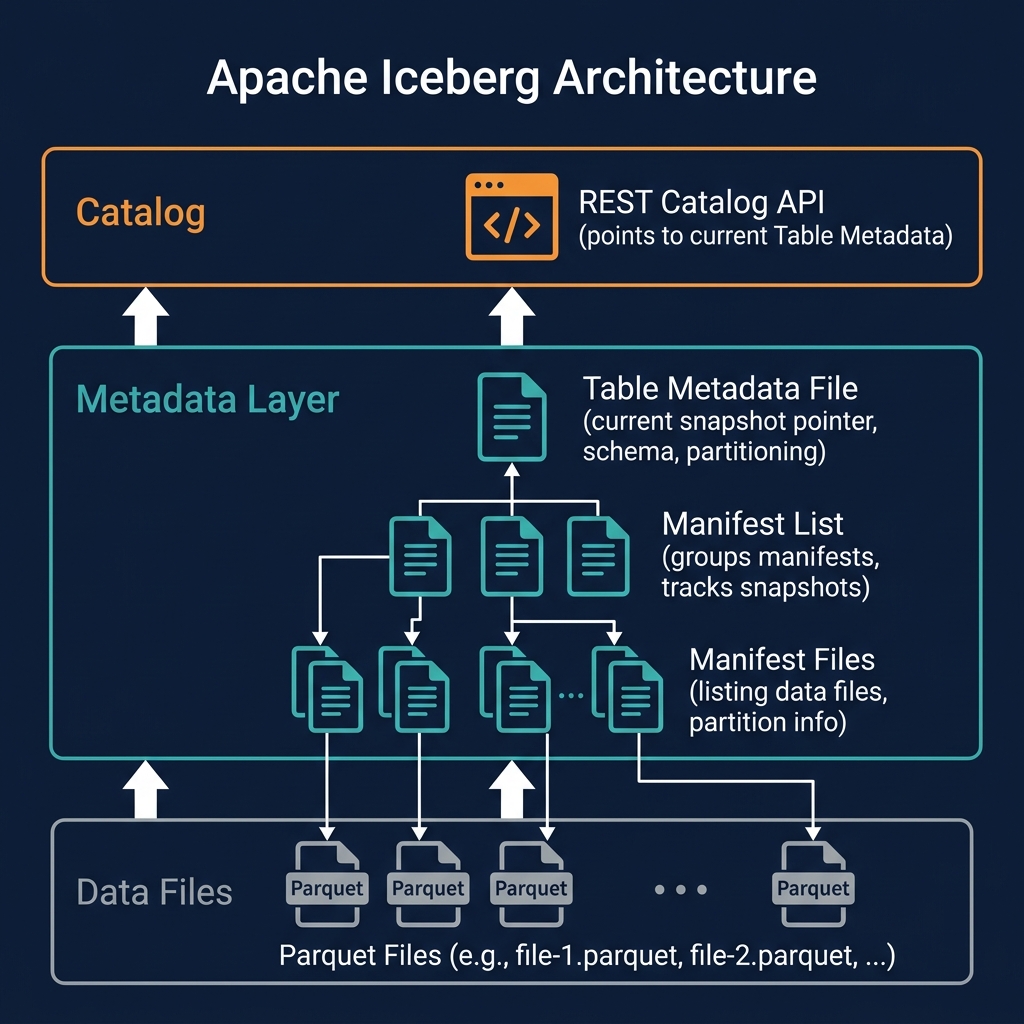
How CoW Updates Work in Iceberg
The CoW UPDATE process in Iceberg follows these steps:
- The query engine applies the WHERE clause to Iceberg metadata, identifying which data files contain rows matching the update predicate
- For each affected file, the engine reads the file, applies the UPDATE expression to matching rows, and writes a new file containing all rows (updated and unchanged)
- The new files and the deletion of the old files are recorded in a new manifest
- The manifest is committed as a new Iceberg snapshot atomically
The old files are not immediately deleted from object storage — they remain in historical snapshots for time travel. They become eligible for deletion only after the snapshots referencing them are expired.
Non-affected files (those with no rows matching the update predicate) are not read or rewritten — they are simply referenced in the new snapshot's manifests as unchanged.
CoW for Gold Layer Tables
CoW is the optimal write strategy for Gold layer Iceberg tables that are queried heavily by BI tools but updated relatively infrequently (daily or weekly batch loads).
In a typical Gold layer workflow: a nightly dbt or Spark job runs an INSERT OVERWRITE to replace the previous day's partition with updated aggregations. This produces clean new files for the updated partition and leaves all other partitions unchanged. The resulting Gold table has clean Parquet files that Dremio can read with maximum efficiency — no delete file merging, no scan overhead.
CoW and MERGE INTO
MERGE INTO in CoW mode combines the logic of matched row updates and unmatched row inserts into a single atomic operation, but each matched file is still rewritten entirely. For MERGE INTO on large tables with frequent updates, this can be expensive.
Best practice for CoW + MERGE INTO: partition the target table so that each MERGE INTO operation touches a small number of partitions. If customer updates are partitioned by bucket(256, customer_id), a MERGE INTO for a batch of 1000 customer updates typically touches only a few buckets — rewriting only those bucket files rather than the entire table.
Optimizing CoW Tables
CoW tables benefit from the following optimizations:
- Right-size partitions: Smaller partitions mean less data to rewrite per UPDATE. Target partition sizes of 128MB–512MB so that a partition rewrite is fast.
- Batch updates: Instead of running many small UPDATE statements that each trigger file rewrites, batch changes and run a single MERGE INTO that rewrites each affected file once.
- Regular compaction: After many small inserts (from streaming micro-batches), compact small files before they accumulate further. Smaller files reduce per-update rewrite cost.
- Dremio Reflections: For Gold CoW tables, configure Reflections on heavily queried aggregations. Reflections absorb the query load, reducing the need for frequent Gold-layer updates by pre-computing common query results.
Summary
Copy-on-Write is Apache Iceberg's write strategy for read-optimized tables. By rewriting affected data files completely on every UPDATE or DELETE, CoW produces clean Parquet files with no merge overhead at read time — ideal for the Gold layer of the Medallion Architecture where BI queries dominate. The trade-off is higher write amplification, which limits CoW's suitability for high-frequency update workloads. For those, Merge-on-Read is the appropriate strategy.