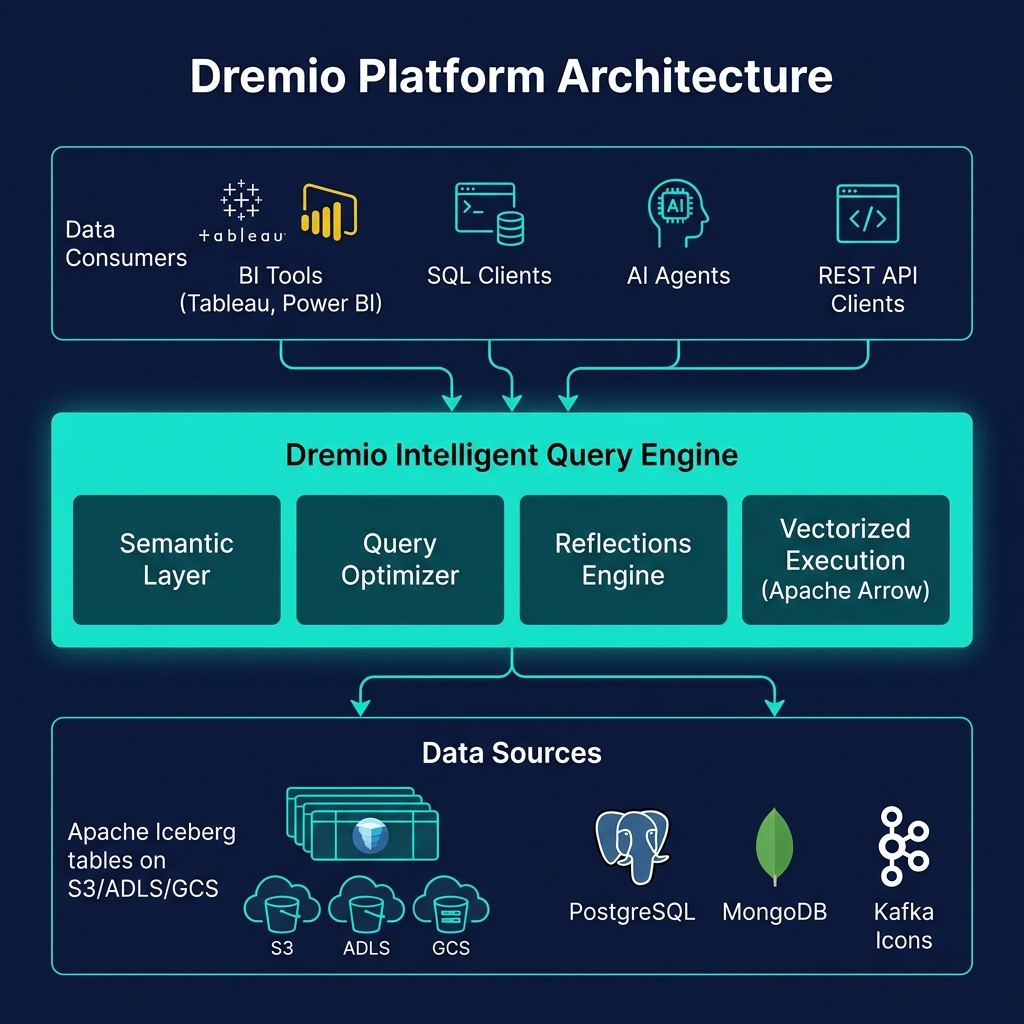
What Is the Dremio Intelligent Query Engine?
Dremio's Intelligent Query Engine is the SQL execution core of the Dremio platform — the component responsible for receiving SQL queries, planning optimal execution strategies, and producing results as fast as possible from Apache Iceberg data and federated sources. It is built on Apache Arrow for vectorized in-memory processing and integrates Reflection matching, multi-level predicate pushdown, and adaptive query execution into a unified planning and execution pipeline.
The 'intelligent' qualifier reflects three capabilities that distinguish Dremio's engine from a simple SQL executor: it automatically identifies and uses the best available Reflection for each query (transparent materialized query routing), it adapts its execution plan at runtime based on actual data characteristics rather than static statistics (adaptive execution), and it understands the semantic meaning of queries within the context of Virtual Dataset definitions (semantic-aware optimization).
Query Planning in Dremio
Every SQL query submitted to Dremio flows through a multi-phase planning pipeline:
- Parsing: SQL text is parsed into an abstract syntax tree (AST)
- Validation: Column references and function names are validated against the catalog's schema
- Logical planning: The AST is converted to a logical query plan — a tree of relational algebra operators (Scan, Filter, Project, Aggregate, Join)
- Reflection matching: The optimizer checks whether any Reflection can serve as a substitute for part or all of the query plan — replacing a raw Iceberg scan with a pre-computed Reflection scan
- Physical planning: The logical plan is converted to a physical execution plan — specific operators (HashAggregate, HashJoin, VectorizedScan) with partitioning and distribution strategies
- Pushdown application: Predicates are pushed into Iceberg metadata readers and Parquet column readers
- Distribution planning: The plan is split across executor nodes for parallel execution
Vectorized Arrow Execution
Dremio's execution engine processes data in Apache Arrow RecordBatches — columnar memory buffers of fixed size (typically 4096 rows). Every operator in the execution pipeline — scan, filter, project, aggregate, join, sort — operates on Arrow batches, applying vectorized SIMD operations that process 8–32 values per CPU instruction.
Data flows through the pipeline without serialization: each operator receives Arrow RecordBatches from the previous operator and produces Arrow RecordBatches for the next. Memory is managed with a shared Arrow memory pool that minimizes allocation overhead. Results returned to clients via Arrow Flight SQL are delivered in Arrow format directly — zero-copy for Python/PyArrow clients.
Adaptive Query Execution
Dremio's Intelligent Query Engine implements adaptive query execution — the ability to adjust the query execution plan at runtime based on actual data characteristics observed during execution, rather than relying entirely on pre-execution statistics estimates.
Adaptive execution addresses a fundamental challenge in query optimization: the optimizer must make decisions (join order, aggregation strategy, partition count) before it has seen the actual data. When statistics are stale or missing, the optimizer's estimates may be wrong, leading to poor execution plans. Adaptive execution detects these situations mid-query and adjusts — for example, switching from a hash join to a broadcast join when an input turns out to be much smaller than estimated, or repartitioning an aggregation when cardinality estimates were wrong.
Summary
Dremio's Intelligent Query Engine is the technical core that makes the open data lakehouse competitive with proprietary cloud warehouses for BI performance. Its combination of Arrow vectorized execution, automatic Reflection routing, multi-level Iceberg predicate pushdown, and adaptive execution creates a query engine that is simultaneously open (reads open Iceberg format), fast (sub-second for accelerated queries), and intelligent (self-optimizing based on actual workload and data characteristics). For organizations building on Apache Iceberg, Dremio's query engine is the component that transforms open data into analytical performance.