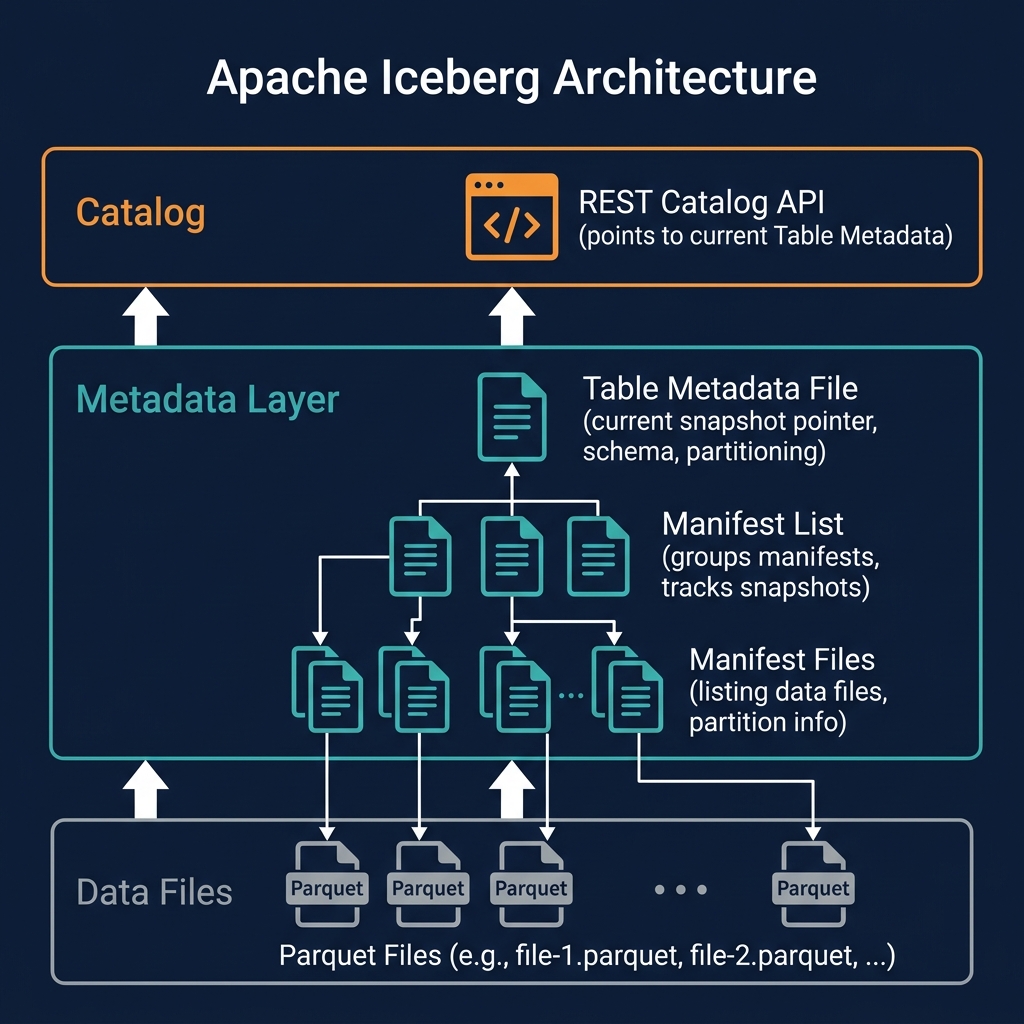
What Is Merge-on-Read?
Merge-on-Read (MoR) is the write strategy in Apache Iceberg (V2+) where UPDATE and DELETE operations write small auxiliary delete files alongside existing data files, rather than rewriting the data files. The merge — reconciling data files with delete files to produce the correct view of the table — is deferred to query time.
MoR's fundamental advantage is write efficiency. Deleting one row from a 500MB data file in MoR mode costs the I/O of writing a tiny delete file (a few kilobytes) rather than reading and rewriting the entire 500MB file. For workloads with thousands of record-level changes per minute — such as CDC pipelines from production databases — this write efficiency difference is the factor that makes the lakehouse practical.
The trade-off is increased read overhead: queries must read both data files and their associated delete files, then merge them to filter out deleted rows and apply updated values. For tables with large delete file accumulation, this merge overhead can significantly slow down reads. Compaction (rewriting MoR data+delete files into clean CoW files) is the maintenance operation that restores read performance.
Iceberg V2 Delete File Types
Iceberg V2 defines two delete file types, each optimized for different use cases:
Positional Delete Files
A positional delete file records the exact location (file path + row position) of each deleted row. When a query reads a data file, it checks the positional delete file: rows at the recorded positions are skipped. Positional deletes are efficient for point-in-time snapshot reads and for sparse, random row deletes — the file path + position record is small and indexable.
Equality Delete Files
An equality delete file records the column values that identify rows to delete — for example, customer_id = 'abc123'. When a query reads data files, it applies the equality delete predicates: rows whose column values match any equality delete record are filtered out. Equality deletes are natural for CDC MERGE INTO workloads, where the source system identifies records by a natural key rather than a physical position.
MoR Write Flow
The MoR write flow for a DELETE operation:
- The engine applies the WHERE clause to Iceberg metadata, identifying which data files contain rows matching the delete predicate
- For each affected data file, the engine writes a positional delete file recording the positions of deleted rows within that file
- The new delete files are recorded in a new manifest alongside their associated data files
- A new snapshot is committed referencing the new manifest
No data files are rewritten. The affected data files remain in storage unchanged; the delete files mark which rows within them should be excluded from query results. The entire write operation touches only a tiny fraction of the data's total size.
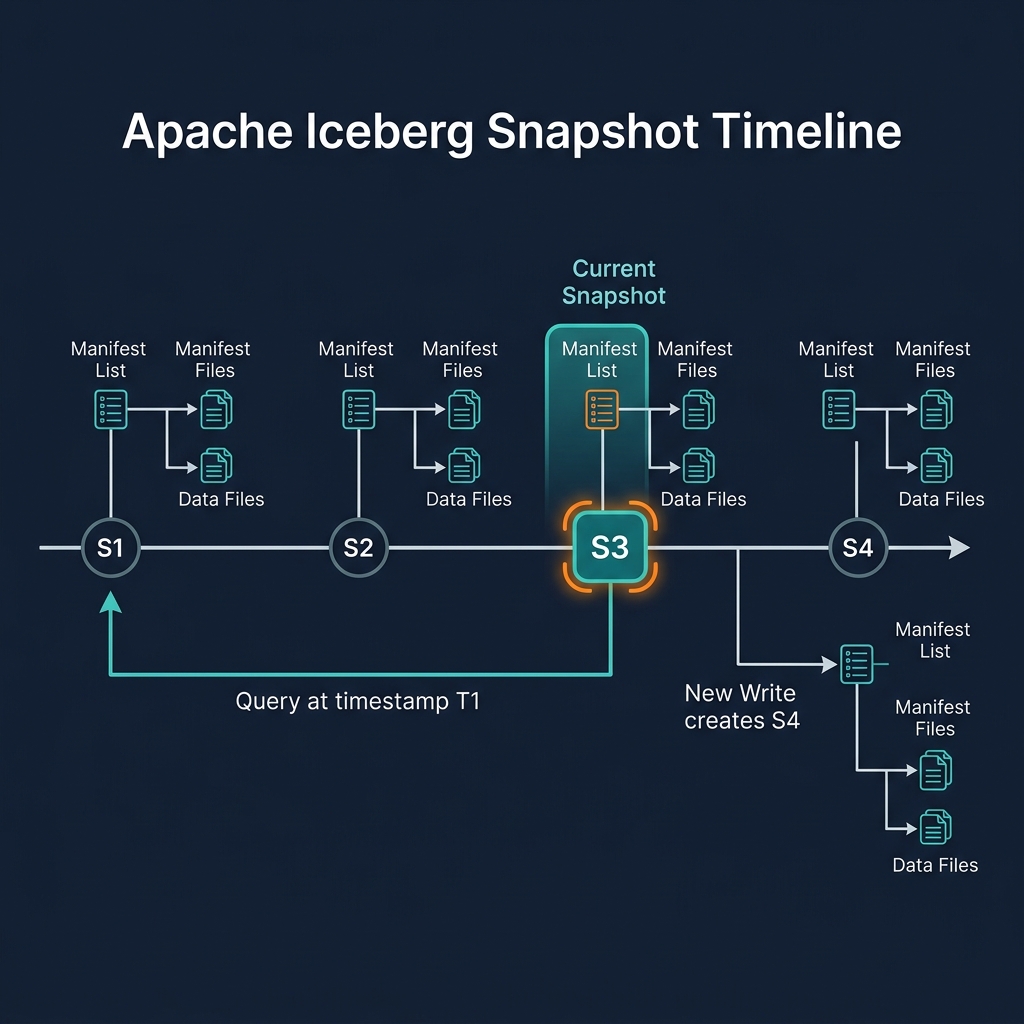
MoR Read Overhead and Compaction
MoR's write efficiency comes at the cost of read overhead. Each query against a MoR table must:
- Read data files
- For each data file, check for associated delete files
- For positional deletes: skip rows at the recorded positions
- For equality deletes: filter rows matching the equality predicates
As delete files accumulate from many CDC operations, this merge overhead grows. A table that was initially fast to read becomes progressively slower as delete files pile up. Scheduled compaction (using Iceberg's RewriteDataFiles with delete file handling) merges data and delete files into clean CoW files, restoring read performance. Dremio's automated table optimization handles this transparently.
MoR for CDC Pipelines
MoR is the standard write strategy for CDC pipeline targets in the Silver layer. A typical CDC pipeline flow with MoR:
- Source database changes are captured by Debezium as Kafka events
- Flink or Spark Structured Streaming reads Kafka events and writes them to Bronze Iceberg tables (append-only)
- A Silver transformation job runs MERGE INTO against the Silver Iceberg table (MoR mode): inserts new records, updates existing records (writes equality delete + new insert), deletes removed records (writes equality delete)
- Periodic compaction merges accumulated delete files into clean Silver data files
This pattern delivers near-real-time data freshness in Silver with manageable operational complexity.
Choosing Between MoR and CoW
The write frequency and read/write ratio should drive the CoW vs MoR decision:
- Gold layer tables: Use CoW. Reads dominate; batch partition overwrites are the primary write pattern. Clean files without delete overhead maximize BI query performance.
- Silver layer with frequent CDC updates: Use MoR. Write frequency is high; write cost of CoW would be prohibitive. Schedule regular compaction to manage delete file accumulation.
- Bronze layer: Append-only. Neither CoW nor MoR applies — no UPDATE or DELETE operations at the Bronze layer.
Summary
Merge-on-Read is Apache Iceberg's write strategy for high-frequency update workloads. By writing small delete files instead of rewriting entire data files, MoR makes CDC upsert pipelines practical at scale. The read overhead from delete file accumulation is managed through regular compaction, which merges delete files into clean data files and restores read performance. Understanding when to use MoR vs Copy-on-Write is fundamental to designing efficient Iceberg table pipelines.