What Is ELT?
ELT — Extract, Load, Transform — is a data integration paradigm where data is extracted from source systems, loaded directly into the destination storage in its raw or lightly processed form, and then transformed in the destination using the destination system's native compute capabilities.
This is a deliberate reversal of the traditional ETL (Extract, Transform, Load) ordering. In ETL, transformation happens in a staging area before the destination sees any data — only clean, transformed data reaches the warehouse. In ELT, the destination receives raw data first; transformation is a subsequent, in-destination operation.
ELT became dominant in the mid-2010s for two reasons: the rise of cheap, scalable cloud storage made it economical to store raw data indefinitely, and the rise of powerful cloud compute (Spark, cloud SQL engines) made in-destination transformation fast enough to be practical. When you can store a terabyte of raw data for $23/month and transform it in minutes with a 100-node Spark cluster that costs $0.10/node-hour, the case for pre-loading transformation in a staging area collapses.
In the modern data lakehouse, ELT maps directly to the Medallion Architecture: Extract from source systems, Load into Bronze Apache Iceberg tables, Transform using dbt, Apache Spark, or Dremio SQL to produce Silver and Gold tables. This is the reference pattern for every modern lakehouse data pipeline.
ELT vs. ETL: The Key Differences
Understanding when to choose ELT over ETL requires clarity on their differences in design philosophy, tooling, and operational trade-offs:
Data Preservation
The most significant difference between ELT and ETL is raw data preservation. In ETL, only transformed data is loaded into the destination — the original raw records are typically discarded after the pipeline runs. In ELT, raw data is loaded into the destination (the Bronze layer) and preserved indefinitely. This enables full reprocessing: if a business rule is found to be incorrect, the Silver and Gold transformations can be rerun from the preserved raw data without re-extracting from the source system.
Transformation Location
In ETL, transformation logic runs on a dedicated ETL server or in a staging area — separate infrastructure that must be sized, maintained, and monitored independently. In ELT, transformation runs in the destination using the destination's native compute — Spark jobs, dbt models, or SQL queries in Dremio. This eliminates the separate transformation infrastructure and concentrates compute investment in the destination platform.
Data Availability Latency
ELT makes raw data available in the destination immediately after extraction, before transformation is complete. Data engineers can query Bronze tables to validate extraction results and diagnose issues before waiting for the full Silver/Gold transformation pipeline to complete. In ETL, no data is available in the destination until the full transformation is done.
Schema Flexibility
ELT handles schema drift more gracefully. Because raw data lands in Bronze before any transformation is applied, a schema change at the source system affects only the transformation logic (Silver models), not the extraction and loading pipeline. In ETL, a source schema change can break the transformation stage before data even reaches the destination.
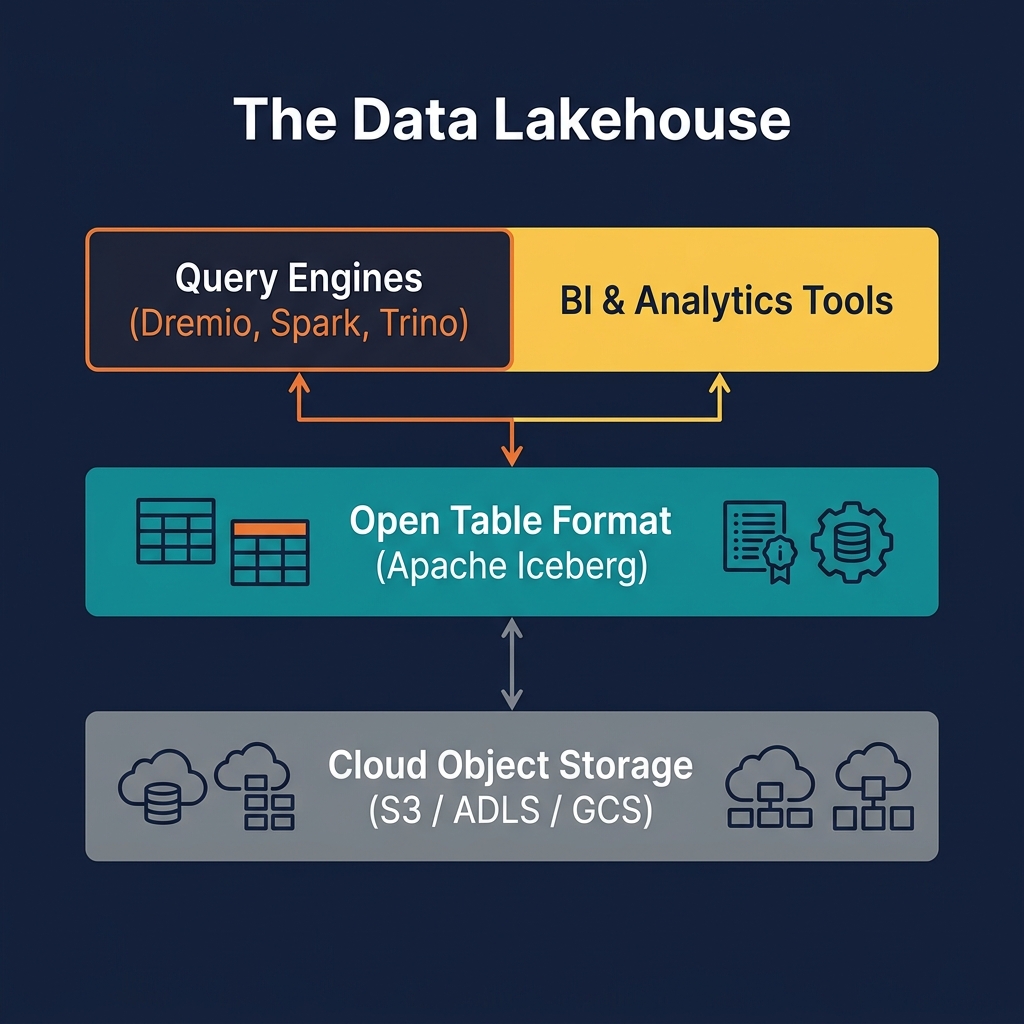
The ELT Pipeline Architecture
A modern ELT pipeline for the lakehouse has three distinct components that can be developed, deployed, and operated independently:
Component 1: Extraction and Loading
Ingestion tools handle the Extract and Load stages. These tools connect to source systems, read data, and write it to Bronze Iceberg tables in cloud object storage. Popular choices:
- Airbyte: Open-source connector platform supporting hundreds of sources. Writes raw records to object storage (S3, ADLS) or directly to Iceberg tables.
- Fivetran: Fully managed connectors for SaaS sources. Strong for Salesforce, HubSpot, NetSuite, and similar API sources.
- Kafka Connect: For streaming extraction from databases via CDC or from Kafka topics produced by application systems.
These tools are intentionally simple: extract, load, done. No transformation logic. This simplicity is by design — keeping transformation out of the extraction tool makes it easier to change transformation logic without modifying the extraction pipeline.
Component 2: Transformation
Transformation tools read from Bronze and write Silver and Gold tables. The two dominant approaches:
- dbt: SQL-based models define each transformation as a SELECT statement. dbt manages dependencies between models, runs them in the correct order, and tests the output. Ideal for analysts and analytics engineers comfortable with SQL.
- Apache Spark: Python or Scala code for complex transformations beyond SQL's expressiveness — machine learning feature engineering, complex event processing, custom deduplication logic.
Component 3: Orchestration
An orchestrator (Apache Airflow, Prefect, Dagster) schedules and monitors the extraction and transformation stages, handles retries on failure, and provides alerting when pipelines fail quality checks. The orchestrator is the glue that connects the three ELT components into a cohesive pipeline.
ELT and the Medallion Architecture
ELT and the Medallion Architecture are natural complements. The Medallion Architecture provides the organizational structure (Bronze/Silver/Gold tiers), and ELT provides the pipeline pattern that populates those tiers:
| Medallion Layer | ELT Stage | Description |
|---|---|---|
| Bronze | Load | Raw, as-extracted records from source systems. No transformation. Schema-on-write enforced by Iceberg. |
| Silver | Transform (stage 1) | Cleaned, deduplicated, type-cast, entity-resolved data. Produced by dbt or Spark from Bronze. |
| Gold | Transform (stage 2) | Business aggregations, dimensional models, ML features. Produced by dbt or Spark from Silver. |
This mapping makes the architecture intuitive to reason about: the EL stages produce Bronze, and the T stages produce Silver and Gold. Each stage can be scaled, optimized, and monitored independently. Failures in the Gold transformation do not affect Bronze or Silver data availability.
The Medallion/ELT combination also enables a powerful capability: schema-version-controlled transformations. When business logic changes, only the Silver and Gold dbt models need to be updated. The Bronze raw data remains unchanged. The updated models can be run as a backfill over historical Bronze data to produce corrected Silver and Gold tables — without any re-extraction from source systems.
dbt: The Dominant ELT Transformation Tool
dbt (Data Build Tool) has become the de facto standard for the Transform stage in ELT pipelines. Its SQL-first approach makes it accessible to data analysts and analytics engineers, not just data engineers with programming expertise.
How dbt Works
In dbt, each transformation is defined as a SQL file — a SELECT statement that reads from source tables (Bronze Iceberg tables or other dbt models) and produces an output table. dbt manages the DAG of dependencies automatically — if model C depends on models A and B, dbt runs A and B before C. dbt materializes each model as a table or incremental table in the destination (Apache Iceberg in the lakehouse case).
dbt Tests
dbt includes a testing framework that runs assertions on model outputs: not-null checks on critical columns, uniqueness checks on primary keys, referential integrity checks (all foreign key values exist in the referenced dimension), and custom SQL tests for business-rule validation. Failed tests block downstream models from running, preventing bad data from propagating through the pipeline.
dbt Documentation
dbt auto-generates documentation for every model — column descriptions, lineage graphs, test results, and freshness metrics. This documentation serves as the data catalog for the Silver and Gold layers, making it easy for analysts to discover and understand available datasets.
dbt with Dremio
Dremio provides a first-class dbt adapter. dbt models execute as SQL queries in Dremio's engine, creating Apache Iceberg tables in Dremio's catalog. Reflections can be configured on dbt-defined Gold models to provide sub-second query performance for BI tools without any changes to the dbt model definitions.
Streaming ELT: Near-Real-Time Pipelines
Traditional ELT runs on a schedule — hourly, daily, or on demand. Streaming ELT applies the same Extract-Load-Transform pattern but operates continuously, processing events as they arrive rather than in batches.
Streaming Extract and Load
Apache Kafka captures change events from source systems (via CDC connectors like Debezium) and delivers them to a streaming consumer. Apache Flink or Spark Structured Streaming reads from Kafka and writes events to Bronze Iceberg tables in micro-batches — typically every 30 seconds to 5 minutes. This produces Bronze tables that are continuously updated with near-real-time data.
Streaming Transform
A continuous Flink job reads from Bronze, applies Silver transformations (deduplication, MERGE INTO for upserts), and writes to Silver Iceberg tables in near-real-time. More complex Gold transformations (aggregations with time windows) can also be implemented as streaming jobs, producing Gold tables that are updated every few minutes.
Trade-offs
Streaming ELT achieves data freshness measured in minutes rather than hours, but at significantly higher operational complexity. Streaming jobs require continuous monitoring, checkpointing for fault tolerance, careful backpressure management, and specialized expertise. For most analytical use cases, hourly or sub-hourly batch ELT achieves sufficient freshness without the complexity of continuous streaming. Reserve streaming ELT for use cases with strict latency requirements: fraud detection, real-time dashboards, operational analytics.
ELT Data Quality and Testing
Data quality in ELT pipelines requires quality checks at every stage boundary:
Post-Load Quality (Bronze)
After raw data is loaded to Bronze, validate that the source sent a plausible record count (not zero, not an order of magnitude higher than historical volumes), that the schema matches expectations, and that key identifier columns are non-null. These checks catch extraction failures before bad data propagates to Silver.
Post-Transform Quality (Silver)
After Silver transformation, validate deduplication (unique record counts match expectations), null rates on critical columns, and referential integrity between joined entities. dbt's built-in test framework is the standard mechanism for Silver quality checks.
Post-Aggregation Quality (Gold)
After Gold aggregation, validate that totals (revenue, count of orders) fall within historical norms using statistical anomaly detection. Sudden spikes or drops in Gold metrics often indicate upstream data issues that passed Silver quality checks but were amplified by aggregation.
Data Observability
For production ELT pipelines, purpose-built data observability tools (Monte Carlo, Bigeye) continuously monitor table freshness, volume, schema, and distribution metrics across all three Medallion layers, alerting when any metric deviates from historical norms — even without explicit quality rules.
ELT at Scale: Performance Considerations
As data volumes grow, ELT pipelines face scaling challenges that require careful engineering:
Incremental Transformation
Transforming the entire Bronze table on every pipeline run becomes impractical as Bronze grows to terabytes. dbt's incremental model materialization reads from Bronze using a watermark filter (WHERE ingested_at > last_run_timestamp), processes only new records, and merges them into Silver using MERGE INTO. This keeps transformation runtime constant regardless of total Bronze table size.
Partition Alignment
Bronze and Silver tables should be partitioned consistently — if Bronze is partitioned by ingested_date, Silver should be partitioned by event_date (or a similar logical date column). Misaligned partitioning causes transformation jobs to read large cross-partition ranges, degrading performance. Iceberg's hidden partitioning simplifies this by making partition pruning automatic and transparent.
Compaction of Silver and Gold
Incremental ELT writes produce many small Parquet files in Silver and Gold tables. Regular compaction merges small files into optimally sized ones. Dremio's automated table optimization handles this automatically; Spark-based pipelines require scheduled maintenance jobs.
ELT with Dremio
Dremio plays multiple roles in an ELT architecture:
As a Transformation Engine
SQL-defined Silver and Gold transformations can be executed directly in Dremio using CTAS (CREATE TABLE AS SELECT) statements against Bronze Iceberg tables. Dremio's vectorized query engine is significantly faster than Hive or Presto for complex analytical SQL, making Dremio-based ELT transformations fast and cost-effective.
As a dbt Adapter Target
dbt models run against Dremio's SQL engine, creating Iceberg tables in Dremio's catalog. Dremio's dbt adapter supports all standard dbt materializations: table, view, incremental, and snapshot.
As a Serving Layer
After ELT completes and Gold tables are populated, Dremio serves them to BI tools and analysts through ODBC, JDBC, and Arrow Flight connections. Reflections transparently accelerate Gold queries to sub-second response times, enabling interactive dashboard performance on ELT-produced data.
As an ELT Validator
Dremio's interactive SQL interface allows data engineers to validate each stage of the ELT pipeline in real time — running ad-hoc quality checks on Bronze tables, previewing Silver transformation results before committing them to production, and profiling Gold data distributions to detect anomalies.
Summary
ELT — Extract, Load, Transform — is the foundational data integration pattern for the modern data lakehouse. By loading raw data into the Bronze layer first and transforming it in the destination using powerful distributed compute, ELT provides three capabilities that traditional ETL cannot match: raw data preservation for full reprocessing, faster data availability, and simpler pipeline architecture.
The Medallion Architecture is the natural organizational framework for ELT in the lakehouse — Bronze captures the raw load, Silver and Gold represent the two-stage transform. Apache Iceberg provides the ACID transactional foundation that makes each stage reliable. dbt provides the SQL-based transformation framework that makes Silver and Gold production accessible to analytics engineers. And Dremio serves the Gold output with sub-second performance, completing the path from raw source data to business-ready analytics.