What Is Presto?
Presto is an open-source, distributed SQL query engine originally developed at Facebook (now Meta) in 2012 and open-sourced in 2013. It was designed to enable interactive SQL analytics across Meta's massive data infrastructure — petabytes of data in HDFS, Hive tables, MySQL databases, and proprietary stores — with sub-minute query latency at any scale.
Presto's architectural innovation was the MPP (massively parallel processing) SQL execution model applied to federated data sources: a single Presto cluster with a Coordinator and hundreds of Workers can query simultaneously across HDFS, S3, relational databases, and other sources using standard SQL, without requiring data to be centralized first.
In 2020, the Presto open-source community forked into two projects: Presto (maintained by the Presto Foundation, primarily Meta engineers) and Trino (the renamed PrestoSQL, maintained by an independent community). Both projects share the original Presto architecture but have diverged in implementation details and ecosystem direction.
Presto Architecture
Presto's architecture is the MPP model that influenced all subsequent distributed SQL engines:
- Coordinator: Receives SQL queries, parses and plans them using the Presto planner and Raptor optimizer, then distributes execution stages to Workers
- Workers: Execute plan fragments in parallel, reading from data sources via Connectors and exchanging data between Workers via the Shuffle layer
- Connectors: Plugin interfaces that translate SQL operations into source-specific reads — Iceberg, Hive, JDBC, Kafka, etc.
- Memory management: Presto uses spill-to-disk for memory-intensive operations (large aggregations, sorts), enabling queries that exceed available cluster memory
Presto and Apache Iceberg
Presto supports Apache Iceberg through the Iceberg connector. Presto's Iceberg support covers: reading Iceberg V1 and V2 tables, partition pruning via hidden partitioning, time travel queries, and basic write operations. Presto's Iceberg catalog support includes Hive Metastore and REST catalogs.
Compared to Trino, Presto's Iceberg connector is somewhat less feature-complete for writing (particularly for complex V2 operations), though both engines provide production-grade Iceberg reads. For organizations primarily using Presto as a read engine against Iceberg tables (written by Spark or Flink), the difference is minimal.
Presto vs. Trino: Which to Choose?
For organizations starting fresh in 2025, the guidance is:
- Choose Trino if: you want the most active open-source community, the fastest release cadence, the strongest Iceberg REST catalog support, or you are using Starburst Galaxy as a managed service
- Choose Presto if: your organization already runs Presto at scale and the migration cost outweighs the benefits, or if you are at Meta-scale and need Presto's spill-to-disk and native Meta optimizations
- Consider AWS Athena if: you are on AWS and want serverless Trino/Presto-compatible SQL without any cluster management
Summary
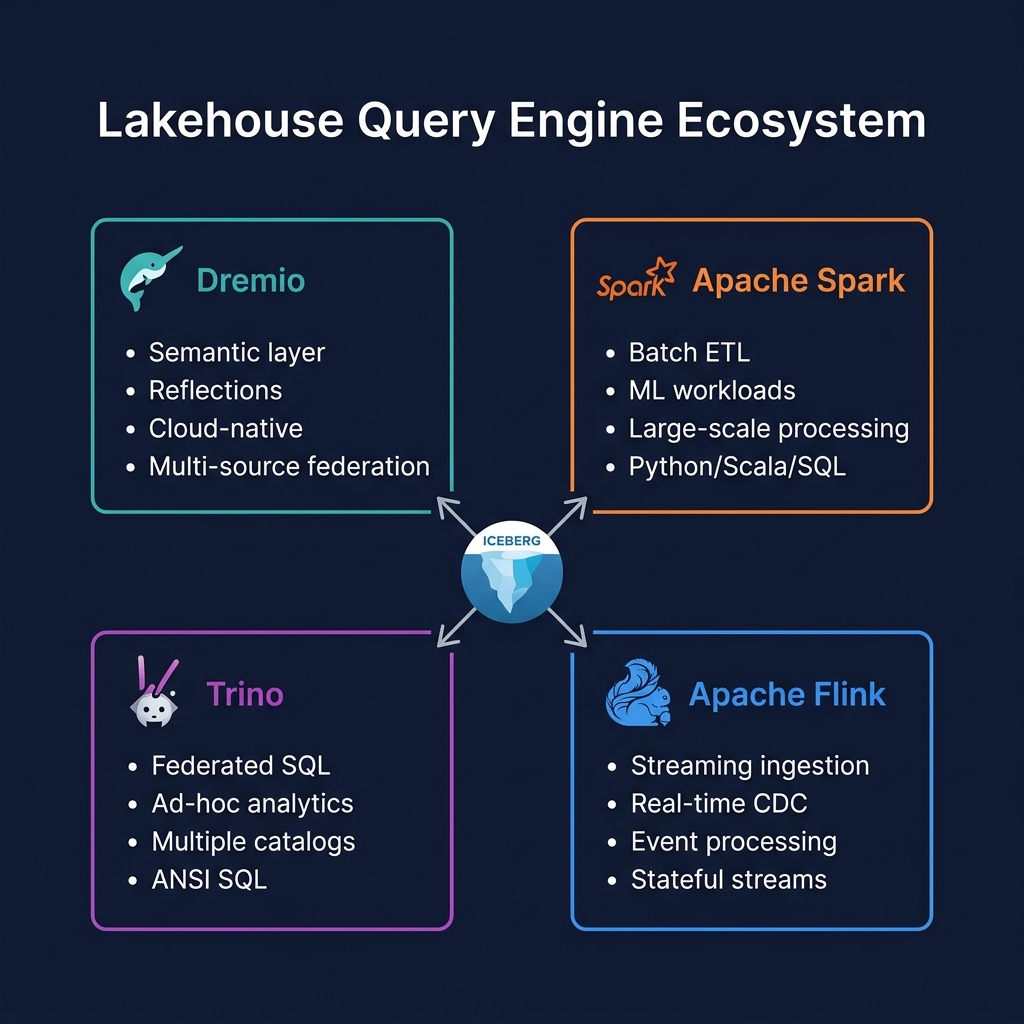
Presto pioneered distributed federated SQL analytics and remains a production-grade engine at some of the world's largest scale deployments. For most new data lakehouse projects in 2025, Trino is the preferred choice given its more active community and stronger Iceberg ecosystem. For organizations already running Presto or operating at Meta-equivalent scale, Presto's battle-tested architecture and performance remain compelling. Both engines are part of a healthy lakehouse ecosystem alongside Dremio (BI analytics) and Spark (batch ETL).