What Is Trino?
Trino (originally PrestoSQL, renamed in 2021) is an open-source, distributed SQL query engine designed for fast, interactive analytics across heterogeneous data sources. Originally developed at Facebook as Presto in 2012, Trino enables a single ANSI SQL query to span multiple, disparate data sources — Apache Iceberg tables in S3, PostgreSQL databases, MySQL tables, Kafka streams, and dozens of other sources — without any data movement or ETL.
Trino's architecture is a massively parallel processing (MPP) SQL engine: a Coordinator node receives queries, plans execution, and distributes work to Worker nodes that execute in parallel against the various data sources. Results are streamed back to the Coordinator and returned to the client. Trino uses a plugin-based Connector model — each data source (Iceberg, Hive, PostgreSQL) is a connector that translates SQL operations into source-specific data reads.
Trino and Apache Iceberg
Trino has strong, production-grade Apache Iceberg support through the Iceberg connector. Trino can read and write Iceberg tables using any compliant catalog: Iceberg REST catalog (including Dremio Open Catalog, Apache Polaris), AWS Glue, Project Nessie, and Hive Metastore with Iceberg format.
Trino's Iceberg capabilities include: full DDL (CREATE, ALTER, DROP), INSERT and MERGE INTO (using CoW semantics), time travel queries (AT SNAPSHOT and AT TIMESTAMP), schema evolution, partition pruning via hidden partitioning, and table optimization procedures. Trino's Iceberg connector is among the most actively maintained in the ecosystem, with strong participation from the Trinopolis and Starburst communities.
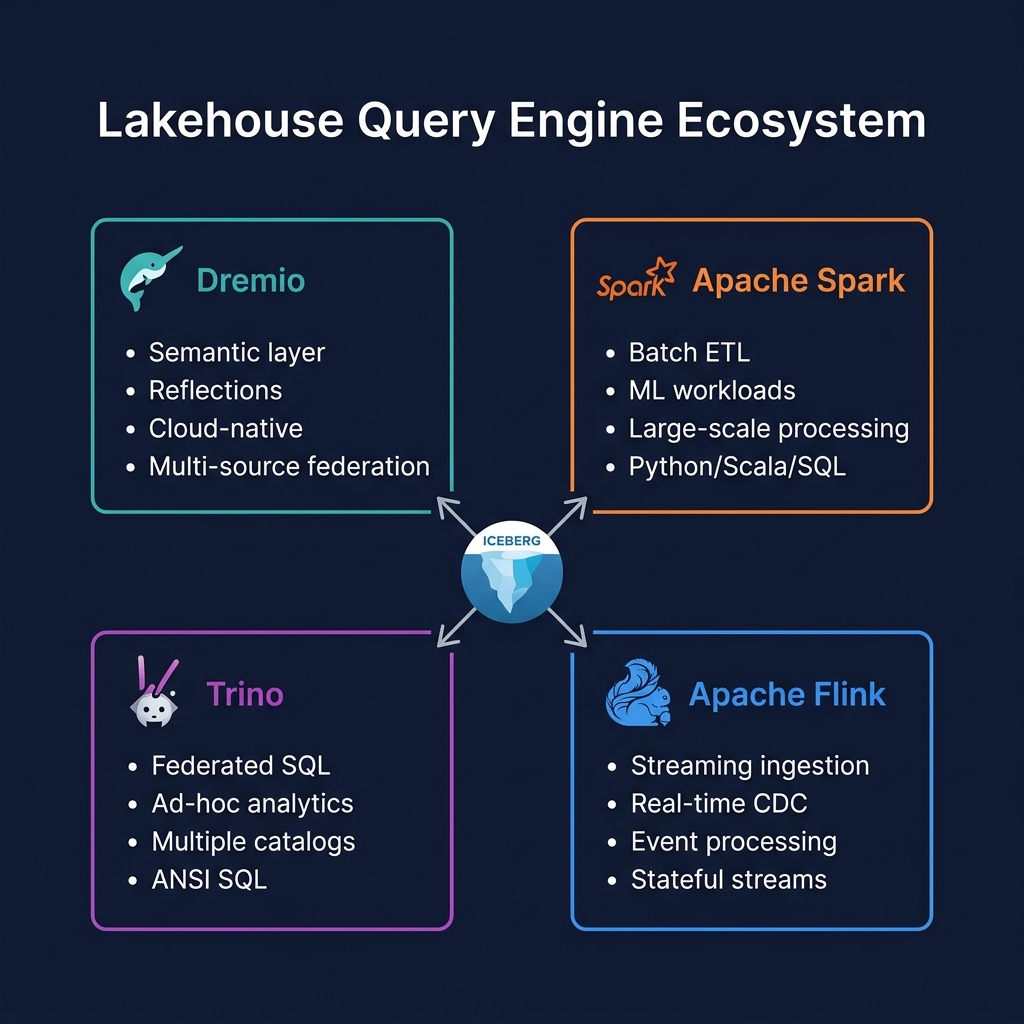
Trino vs. Dremio vs. Spark
| Dimension | Trino | Dremio | Apache Spark |
|---|---|---|---|
| Primary strength | Federated ad-hoc SQL | BI + Semantic layer | Batch ETL + ML |
| Startup latency | Low (always-on) | Low (always-on) | High (cluster startup) |
| BI tool optimization | None (no materialization) | ✅ Reflections | None |
| Semantic layer | None built-in | ✅ Virtual Datasets | None |
| Multi-catalog | ✅ Best-in-class | Good | Good (with config) |
| ML workloads | Not applicable | Not applicable | ✅ MLlib, PySpark |
Trino Ecosystem: Starburst and AWS Athena
Trino has a rich commercial ecosystem:
Starburst
Starburst is the enterprise Trino distribution, providing the Trino engine with enterprise features: role-based access control, audit logging, data products, and a managed SaaS offering (Starburst Galaxy) on AWS, Azure, and GCP. Starburst engineers are among the largest contributors to open-source Trino.
AWS Athena
Amazon Athena is AWS's serverless interactive query service, built on Trino's engine (Athena v3). It is fully managed, pay-per-query, and natively integrates with S3, Glue catalog, and Iceberg tables — making it the easiest way to run Trino-compatible SQL on AWS without any infrastructure management.
Summary
Trino is the premier open-source engine for federated, ad-hoc SQL analytics across heterogeneous data sources in the data lakehouse. Its connector model, strong Apache Iceberg support, and ANSI SQL compliance make it the default choice for organizations building open, multi-source analytics platforms without proprietary engine lock-in. In the lakehouse stack, Trino complements Spark (batch ETL) and Dremio (BI + semantic layer) to provide comprehensive query coverage across all analytics workload types.