What Are ACID Transactions?
ACID transactions are a set of four properties that guarantee reliable processing of database operations, even in the presence of errors, concurrent access, and system failures. The acronym stands for Atomicity, Consistency, Isolation, and Durability. Together, these four properties ensure that data modifications are reliable, predictable, and safe.
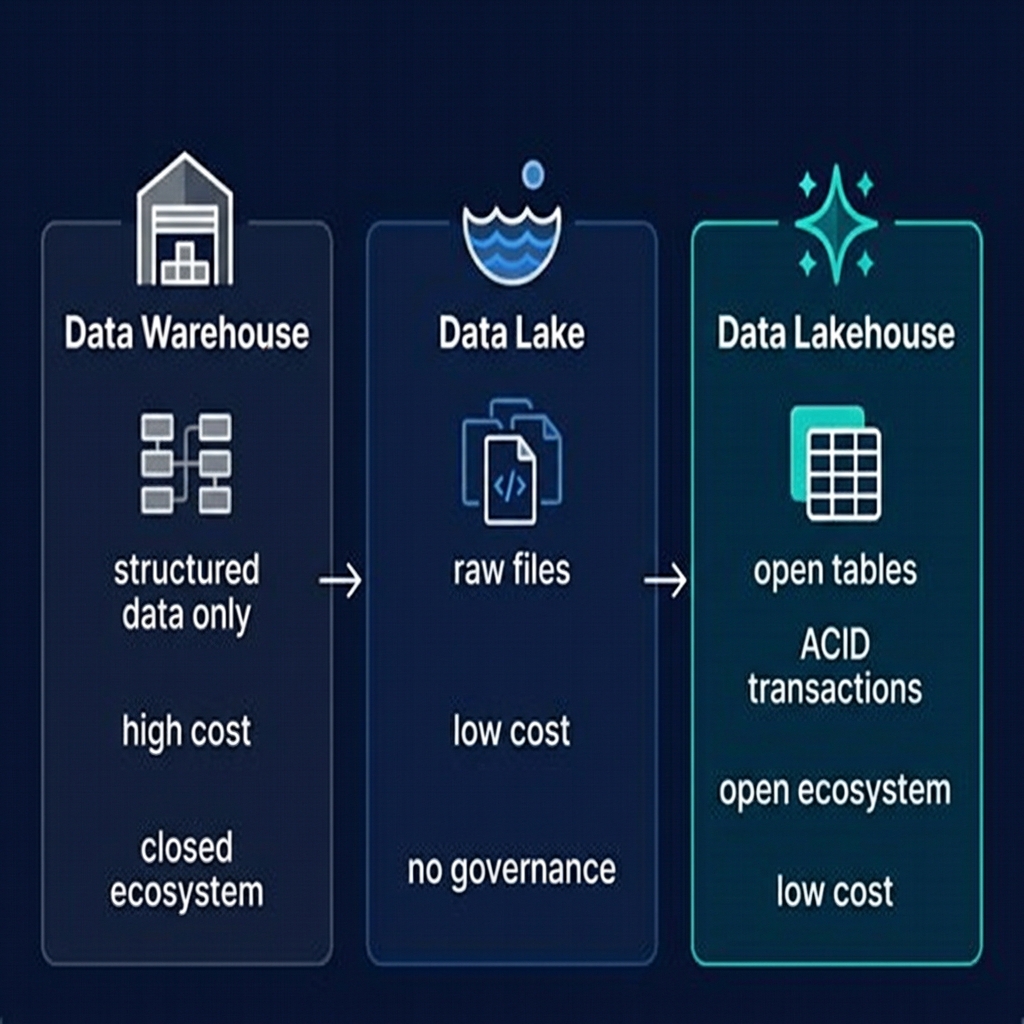
ACID was first formally defined by Andreas Reuter and Theo Härder in 1983 as a framework for evaluating database transaction management systems. For four decades, ACID compliance was the exclusive domain of relational databases and data warehouses — systems that stored data in proprietary, tightly controlled formats. The raw data lake, by contrast, provided none of these guarantees, which was the primary reason it was unsuitable for production analytical workloads that required reliable, consistent data.
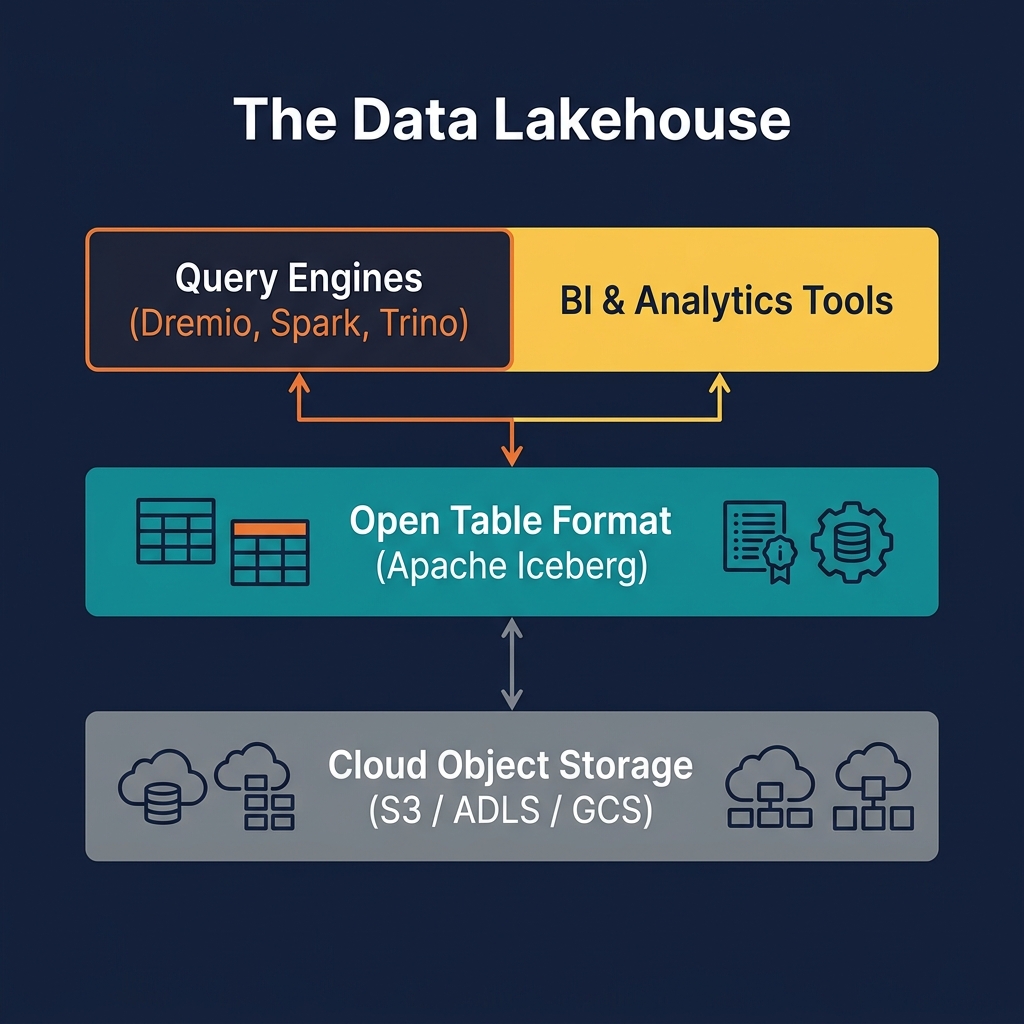
The emergence of open table formats — particularly Apache Iceberg — changed this. By adding a transactional metadata layer on top of immutable files in cloud object storage, Iceberg brings true ACID semantics to the data lakehouse. This is one of the most significant technical achievements in the history of data engineering: ACID guarantees on petabyte-scale, multi-engine, open storage.
Understanding ACID transactions in the lakehouse context requires understanding what each property means, why it matters for analytical workloads, and how Apache Iceberg implements it on infrastructure (cloud object storage) that was never designed to support transactions.
Atomicity: All or Nothing
Atomicity means that a transaction either completes entirely — all its operations succeed — or has no effect at all. There is no intermediate state where some operations have succeeded and others have not. If a transaction is interrupted midway — by a network failure, a process crash, or an out-of-memory error — the database rolls back to its state before the transaction began, as if the transaction never happened.
Why Atomicity Matters in the Lakehouse
Consider an ETL job that writes a new daily partition to a Silver layer table. The job writes 200 Parquet files to S3, each containing a batch of rows. If the job crashes after writing file 150, what does the table look like?
Without atomicity, the table contains 150 new files alongside the previous state — a corrupted, half-updated partition that will produce incorrect query results for any analyst querying data from that day. Resolving this requires manually identifying and deleting the 150 partial files — a tedious and error-prone process.
With Apache Iceberg's atomicity, no such problem exists. The 150 files are written to object storage, but they are not part of any committed snapshot until the final metadata commit succeeds. If the job crashes, the uncommitted files are simply orphaned — they exist in storage but are invisible to any query engine reading through Iceberg's metadata. A subsequent cleanup operation (Iceberg's expireSnapshots procedure) removes them. Readers see the table in its previous, consistent state throughout the failed write.
How Iceberg Implements Atomicity
Iceberg achieves atomicity through its snapshot commit protocol. A writer collects all its new data files into a new snapshot — a complete description of the table's state after the write. The writer then attempts to atomically swap the table's current metadata pointer from the previous snapshot to the new one. This swap is a single, atomic operation against the catalog. If it succeeds, the transaction is committed. If it fails for any reason, the new files remain in storage but are invisible to readers, and the table retains its previous state.
Consistency: Valid State Transitions
Consistency means that every transaction brings the database from one valid state to another valid state, where validity is defined by the database's schema constraints, integrity rules, and invariants. A transaction that would violate a constraint — inserting a null into a non-nullable column, for example — is rejected before it can corrupt the data.
Consistency in Apache Iceberg
Iceberg enforces consistency through its schema model. Every table has a defined schema — column names, types, and nullability constraints — stored in the table's metadata. When a writer attempts to add data to an Iceberg table, the engine validates that the data conforms to the schema. Type mismatches (writing a string to an integer column) and null violations cause the write to be rejected before any files are committed.
Schema Evolution Without Inconsistency
Iceberg's schema evolution capabilities allow the table's schema to change over time — adding columns, dropping columns, renaming columns — while maintaining consistency. When a new column is added to an Iceberg table, existing data files are not rewritten. Instead, Iceberg's schema metadata records the default value for the new column when reading old files. This means queries that reference the new column return the default value for old records and the actual written value for new records — consistent behavior without data migration.
This is a significant advantage over the data lake's schema-on-read model, where schema changes can silently break existing queries by producing unexpected null values or type errors in historically consistent fields.
Isolation: Concurrent Access Without Interference
Isolation means that concurrent transactions do not interfere with each other. A reader executing a query sees a consistent snapshot of the data as it existed at the start of the query — even if writers are actively modifying the table during the query's execution. A writer does not see the partial state of another concurrent writer's in-progress transaction.
Snapshot Isolation in Apache Iceberg
Iceberg implements snapshot isolation — the highest practical isolation level for analytical workloads. When a reader begins a query, Iceberg identifies the current committed snapshot and reads only the files belonging to that snapshot. Even if multiple writers commit new snapshots during the query's execution, the reader continues to see the snapshot it started with — a fully consistent view of the data.
This is particularly valuable in the Medallion Architecture, where Silver-to-Gold transformation pipelines may run for hours while analysts are simultaneously querying the Gold tables. Without isolation, analysts would see partially updated Gold data during pipeline runs — an inconsistency that could produce incorrect dashboard results and erode trust in the data platform.
Optimistic Concurrency Control for Writers
When multiple writers attempt to commit to the same Iceberg table simultaneously, Iceberg uses optimistic concurrency control to resolve conflicts. Each writer reads the current snapshot, performs its writes, and then attempts to commit a new snapshot by atomically updating the metadata pointer. If another writer has already committed a new snapshot since the first writer read the table, the commit is rejected with a conflict error, and the writer retries from the latest snapshot.
This approach avoids expensive distributed locking while providing serializable isolation between writers. For most lakehouse workloads — where writers operate on non-overlapping partitions — conflicts are rare and retries are infrequent.
Durability: Surviving Failures
Durability means that once a transaction is committed, it remains committed — even in the presence of system failures, crashes, or network outages. The committed data is persisted to durable storage and will survive any foreseeable failure.
Durability in the Lakehouse Context
Durability is the ACID property that cloud object storage provides most naturally. Amazon S3 offers 11-nines (99.999999999%) durability — data is replicated across at least three availability zones automatically. Azure ADLS and Google Cloud Storage provide equivalent guarantees. Once a Parquet file is written to and confirmed by object storage, it will survive any single data center failure, and in most configurations, the simultaneous failure of an entire cloud region.
For Iceberg's transaction metadata, durability requires that the metadata commit to the catalog is atomic and persistent. Catalog implementations like Apache Polaris and Project Nessie use relational databases or distributed consensus systems (Postgres, DynamoDB, RocksDB) as their backing stores, providing the durability guarantees appropriate for a production catalog.
Write-Ahead Logging vs. Iceberg's Approach
Traditional databases achieve durability through write-ahead logging (WAL) — writing changes to a log before applying them to the main storage, so the log can be replayed after a crash. Iceberg achieves durability differently: it writes data files to durable object storage first (before the transaction is committed), then commits the metadata pointer atomically. Because object storage is inherently durable, there is no need for a WAL — the data files themselves serve as the write-ahead log, and the metadata commit is the transaction's commit record.
ACID in Practice: INSERT, UPDATE, DELETE, MERGE
ACID semantics in the data lakehouse enable the full range of DML (Data Manipulation Language) operations that data engineers and analysts expect from a mature data platform:
INSERT
Inserting new rows appends new Parquet files to the table and creates a new Iceberg snapshot referencing those files. The insert is atomic — readers see either the complete new rows or the previous state, never a partial insert. INSERT operations in Iceberg are extremely efficient because they never rewrite existing files.
UPDATE and DELETE
Updates and deletes are implemented using one of two strategies — Copy-on-Write (CoW) or Merge-on-Read (MoR). In CoW mode, the affected data files are rewritten with the changes applied, producing new files. The old files remain in storage (accessible via time travel) but are excluded from the new snapshot. In MoR mode, delete files are written alongside the original data files; the query engine merges them at read time to produce the correct view.
MERGE INTO
MERGE INTO (upsert) is the most powerful DML operation in the lakehouse — it conditionally inserts, updates, or deletes rows based on a join condition. This is the primary mechanism for implementing CDC (Change Data Capture) pipelines: records from a source system's changelog are merged into Silver Iceberg tables, updating existing rows and inserting new ones in a single atomic operation.
Dremio supports all four DML operations (INSERT, UPDATE, DELETE, MERGE INTO) against Apache Iceberg tables using standard ANSI SQL syntax, making them accessible to any analyst or data engineer comfortable with SQL.
ACID Transactions and Time Travel
Iceberg's snapshot-based implementation of ACID atomicity produces a natural by-product: time travel. Because every committed transaction creates a new snapshot, and snapshots are retained in the metadata log until explicitly removed, users can query any historical state of a table by referencing its snapshot ID or timestamp.
Time travel is enabled by ACID atomicity: because every write is atomic (either fully committed or not committed at all), every snapshot in the history represents a consistent, complete state of the table. There are no "partial" snapshots — every historical snapshot reflects a point in time where the table was in a valid state.
Practical time travel use cases include:
- Debugging data quality issues: Query the table as it existed before a suspected bad write to compare the before and after states
- Regulatory audit: Reproduce the exact data that was used to generate a regulatory report on a specific date
- ML experiment reproducibility: Ensure that ML training jobs use exactly the same dataset regardless of when they are re-run
- Accidental delete recovery: Recover from an accidental DELETE or table drop by reading from a pre-deletion snapshot and re-inserting the deleted rows
In Dremio, time travel queries use the AT SNAPSHOT or AT TIMESTAMP syntax: SELECT * FROM my_table AT TIMESTAMP '2026-01-01 00:00:00'. This capability is available for any Iceberg table managed through Dremio's catalog without any additional configuration.
ACID Challenges in the Lakehouse
While Apache Iceberg's ACID implementation is robust, several challenges arise in production deployments:
Concurrency Conflicts
In high-write-frequency scenarios — streaming CDC pipelines writing to the same Iceberg table hundreds of times per minute — optimistic concurrency conflicts can become frequent. Each conflict requires a retry, which adds latency and CPU overhead. The solution is to configure streaming writers to use a Merge-on-Read write mode, which reduces per-commit metadata overhead and makes the commit protocol more forgiving of concurrent access.
Metadata Accumulation
Every committed transaction adds new manifest files and snapshot records to the table's metadata. Over time — particularly for tables with many small transactions — the metadata can grow to millions of files, making metadata reads slow. Regular compaction (merging small data files) and metadata cleanup (expiring old snapshots, rewriting manifests) are essential maintenance operations. Dremio's automated table optimization handles these operations automatically.
Cross-Table Transactions
Apache Iceberg's ACID guarantees apply at the table level — a single Iceberg transaction is atomic across all operations within that transaction, but Iceberg does not natively support atomic transactions that span multiple tables. Use cases that require multi-table atomicity — updating a fact table and a dimension table in a single atomic operation — must be handled at the application level, typically by careful pipeline design or by using a catalog that supports multi-table transactions (Project Nessie provides branch-level multi-table atomicity).
ACID Transactions and Dremio
Dremio exposes the full ACID capability of Apache Iceberg through a standard SQL interface. Data engineers and analysts interact with Dremio using familiar SQL statements — no need to understand Iceberg's underlying commit protocol or file layout.
Key Dremio capabilities built on Iceberg ACID:
- Transactional DML: INSERT INTO, UPDATE, DELETE, and MERGE INTO against Iceberg tables are fully ACID-compliant — atomic, consistent, isolated, and durable
- Time travel queries:
AT SNAPSHOTandAT TIMESTAMPsyntax for querying any historical Iceberg snapshot - Rollback: Dremio can roll back an Iceberg table to any previous snapshot, providing a simple recovery mechanism for accidental data changes
- Concurrent query safety: Dremio's query engine is aware of Iceberg's snapshot isolation model and always reads from a consistent snapshot, even on long-running analytical queries
- Automated maintenance: Dremio automatically expires old snapshots and orphan files, preventing metadata accumulation without manual DBA intervention
Best Practices for ACID in the Lakehouse
Implementing ACID transactions effectively in a production lakehouse requires attention to a few key operational patterns:
- Configure write mode based on workload. Use Copy-on-Write (CoW) for tables with infrequent updates and high read frequency. Use Merge-on-Read (MoR) for tables with frequent updates or high-frequency streaming writes.
- Automate snapshot expiration. Retain snapshots for your required time-travel window (typically 7–30 days) and expire older snapshots automatically to prevent metadata bloat. Dremio handles this automatically; Spark jobs require explicit scheduling of
expireSnapshots. - Monitor conflict rates in streaming pipelines. High concurrency conflict rates (more than 5% of commits) indicate a need to redesign the write pattern — either reducing write frequency, using MoR mode, or partitioning writers to operate on non-overlapping data ranges.
- Use MERGE INTO for CDC pipelines. Avoid the anti-pattern of deleting entire partitions and re-inserting data for CDC workloads. MERGE INTO is significantly more efficient and provides proper ACID atomicity for upsert operations.
- Test time travel for disaster recovery. Document and test the time-travel recovery procedure before you need it. Know the syntax for your specific catalog and engine combination, and verify that snapshot retention is configured to cover your recovery point objective (RPO).
Summary
ACID transactions are the cornerstone of a reliable data lakehouse. They provide the guarantees — atomicity, consistency, isolation, durability — that make lakehouse data trustworthy for production analytical workloads, BI dashboards, regulatory reporting, and increasingly, AI and agentic applications.
Apache Iceberg's snapshot-based commit protocol delivers true ACID semantics on cloud object storage — a platform never designed for transactions — through a combination of immutable files, atomic metadata pointer swaps, and snapshot isolation for concurrent readers and writers. This achievement is what separates the modern data lakehouse from its predecessor, the unmanaged data lake.
Dremio surfaces these ACID capabilities through standard SQL, making them accessible to every data practitioner — from data engineers building CDC pipelines with MERGE INTO to analysts using time travel to debug data quality issues to data scientists ensuring ML experiment reproducibility.