What Is a Data Lake?
A data lake is a centralized repository designed to store, process, and analyze large volumes of structured, semi-structured, and unstructured data in its raw, native format. Unlike a data warehouse, which requires data to be transformed and loaded into a rigid, predefined schema before it can be stored, a data lake applies what is known as schema-on-read semantics: data is ingested as-is, and structure is applied only when the data is queried.
The foundational storage layer of a data lake is inexpensive, highly scalable cloud object storage — Amazon S3, Azure Data Lake Storage, or Google Cloud Storage. Files are stored in any format: Apache Parquet, CSV, JSON, Avro, ORC, or even binary formats like images, audio, and video. The storage cost is dramatically lower than proprietary warehouse storage — often 10–50x less per terabyte.
Data lakes emerged around 2010–2014 as a response to the explosion of big data — machine-generated logs, clickstream data, IoT sensor readings, social media — that overwhelmed the ingestion pipelines and storage budgets of traditional data warehouses. Apache Hadoop's HDFS (Hadoop Distributed File System) was the first widely adopted data lake storage layer, followed by cloud object storage as cloud infrastructure matured in the mid-2010s.
The canonical data lake architecture has three components: a storage layer (object storage or HDFS), an ingestion layer (Kafka, Kinesis, or batch ETL tools), and a processing layer (Apache Spark, Hive, or Presto). Data arrives in the storage layer from dozens or hundreds of sources, and analysts or data scientists process it on demand using distributed compute frameworks.
The promise of the data lake was compelling: store everything, pay very little, and let multiple teams analyze the data using the tools they prefer. For organizations generating terabytes of log data per day or ingesting streams of IoT telemetry, the data lake was transformative — it made previously impossible analytics affordable.
The Rise of the Data Lake: Historical Context
The data lake concept was popularized by James Dixon, CTO of Pentaho, who coined the term in a 2010 blog post. Dixon used the metaphor of a lake as contrast to data marts — which he likened to bottled water: pre-packaged, filtered, and purpose-built for specific uses, but limited in volume and flexibility.
The early data lake ecosystem was dominated by Apache Hadoop. HDFS provided distributed block storage, MapReduce provided the compute, and Apache Hive provided SQL-like query capability. But Hadoop was operationally complex — requiring specialized teams to manage clusters — and query performance was measured in minutes or hours, not seconds.
The mid-2010s brought two transformations: the rise of cloud object storage (S3, ADLS, GCS) as a superior replacement for HDFS, and the rise of Apache Spark as a replacement for MapReduce. Cloud storage was cheaper, more durable, and simpler to operate. Spark was dramatically faster than MapReduce for iterative workloads like machine learning and complex ETL.
By 2016–2018, the reference data lake architecture was: cloud object storage as the persistence layer, Apache Spark for processing, and Apache Parquet as the dominant file format for columnar analytics. Tools like AWS Glue, Azure Data Factory, and Google Dataflow simplified data ingestion. This architecture was genuinely powerful — but it had fundamental weaknesses that would only become apparent at scale.
The Apache Hadoop era also established key patterns that persist in modern lakehouses: the separation of storage and compute, the use of columnar file formats, and the principle that data should be stored once and processed many times by different engines.
How a Data Lake Works: Technical Architecture
A data lake operates on a simple principle: ingest first, structure later. Data flows into the lake from source systems through ingestion pipelines — batch ETL jobs, CDC connectors, Kafka streams, or direct API calls — and lands in cloud object storage as files.
Storage Organization
Without a table format, data lake storage is organized into a folder hierarchy by convention. A typical structure might be: s3://my-lake/raw/source-system/entity/year=2026/month=05/day=14/. This Hive-style partitioning scheme allows query engines to prune irrelevant partitions — but only if the partition scheme matches the query's filter predicates, and only if the partition layout doesn't change over time.
Schema-on-Read
In a data lake, schema is not enforced at write time. A CSV file can have any columns in any order. A JSON file can have nested, variable-length structures. The schema is inferred or provided at query time by the engine reading the file. This flexibility is powerful for raw data ingestion — but it means that two writers can produce files with incompatible schemas in the same folder, silently breaking downstream queries.
Query Engines
Data lake query engines include Apache Spark (for large-scale batch and streaming), Trino/Presto (for interactive SQL), Apache Hive, and AWS Athena. These engines connect directly to object storage, read files, and apply schemas at query time. Without metadata management, each engine must scan all files to discover their schemas — an expensive operation on large datasets.
Metadata Catalogs
The Hive Metastore was the dominant metadata catalog for data lakes, tracking table definitions, partition locations, and file paths. AWS Glue Data Catalog extended this pattern to the cloud. But these catalogs were optimized for batch, append-only workloads — they had no concept of transactions, no snapshot isolation, and no fine-grained access control at the table level.
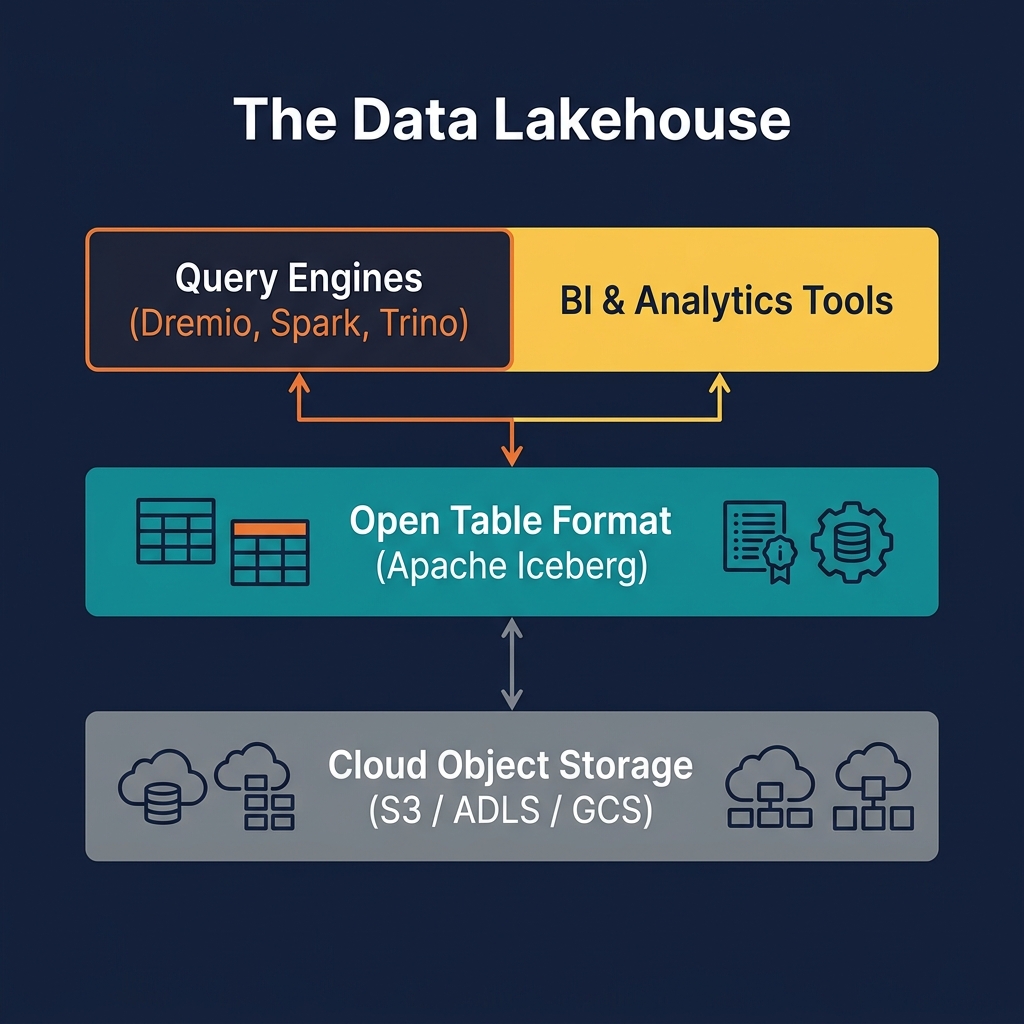
The Data Swamp Problem: Why Data Lakes Failed
The term data swamp — a data lake that has become unmanageable, ungoverned, and unusable — became one of the most commonly cited failure modes in enterprise data architecture by 2018–2020. Understanding why data lakes fail is essential to understanding why the data lakehouse was necessary.
No ACID Transactions
Traditional data lake storage provides no transaction semantics. When two Spark jobs write to the same table concurrently, they can overwrite each other's data or create partially written partitions that appear corrupt to readers. Any reader that executes during a write may see an inconsistent view. Resolving these issues required custom locking mechanisms, careful scheduling, or simply avoiding concurrent writes — all operationally painful.
No Native Update or Delete
Cloud object storage is designed for immutable objects: you can write files and read files, but you cannot edit a file in place. Implementing UPDATE or DELETE in a data lake required reading an entire partition, modifying the data in memory, and rewriting all the files — an expensive full-partition rewrite for every change. For GDPR deletion requests or late-arriving corrected records, this was a serious operational burden.
Metadata and Discoverability
As data lakes grew to hold thousands of tables and billions of files, discovering what data existed became a major challenge. Without a rich metadata catalog, analysts spent hours searching for the right dataset. The Hive Metastore's simple key-value metadata model was insufficient for enterprise governance needs.
BI Tool Incompatibility
Business intelligence tools like Tableau, Power BI, and Looker were designed to connect to SQL databases and data warehouses with JDBC/ODBC. They assumed reliable, consistent data and fast query response times. Raw data lake queries — scanning terabytes of Parquet files without metadata optimization — were far too slow for interactive BI, and the lack of consistent schemas made connections unreliable.
Data Quality Deterioration
Without schema enforcement, data quality in lakes degraded over time. Source system changes broke ingestion pipelines silently. New fields appeared without documentation. Null rates spiked unexpectedly. Without a data quality monitoring layer, these issues went undetected until analysts reported incorrect results.
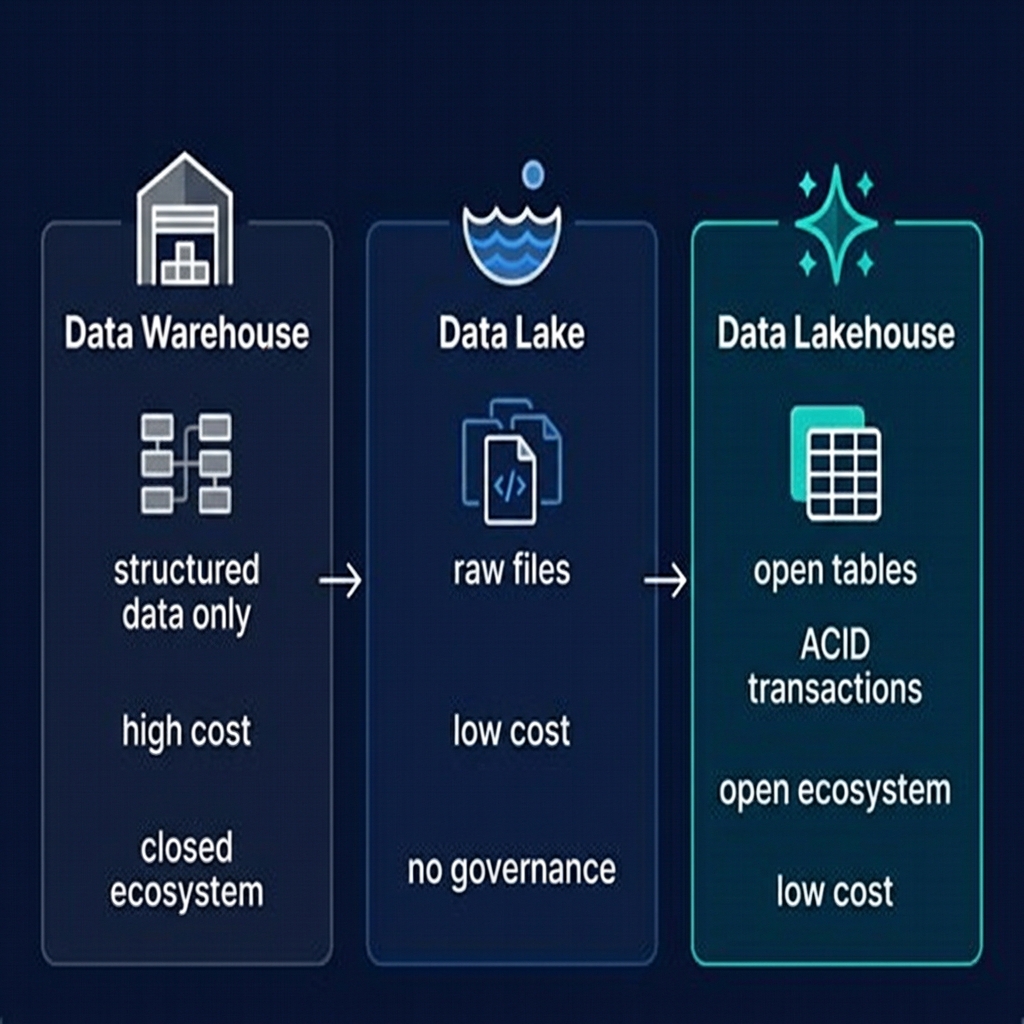
Data Lake vs. Data Warehouse vs. Data Lakehouse
The three paradigms represent an evolution in enterprise data architecture, each addressing the previous generation's shortcomings:
| Feature | Data Lake | Data Warehouse | Data Lakehouse |
|---|---|---|---|
| Schema model | Schema-on-read | Schema-on-write | Schema-on-write via table format |
| ACID transactions | ❌ None | ✅ Yes | ✅ Yes (Apache Iceberg) |
| Storage cost | ✅ Very low | ❌ High | ✅ Very low |
| Update / Delete | ❌ Expensive rewrite | ✅ Native | ✅ Via MoR or CoW |
| BI tool support | ⚠️ Inconsistent | ✅ Excellent | ✅ Excellent |
| ML / AI workloads | ✅ Native | ❌ Difficult | ✅ Native |
| Multi-engine | ✅ Yes | ❌ Single vendor | ✅ Yes |
| Data governance | ❌ Weak | ✅ Strong | ✅ Strong |
| Time travel | ❌ No | ⚠️ Limited | ✅ Yes |
The data lakehouse was designed specifically to take the storage economics and engine flexibility of the data lake and combine them with the transactional reliability and governance of the data warehouse. Apache Iceberg is the mechanism that bridges these two worlds.
Modern Data Lake Use Cases (Where They Still Excel)
Despite the rise of the data lakehouse, pure data lake patterns remain relevant for specific use cases where the overhead of a table format is unnecessary or counterproductive:
Raw Landing Zone
In a Medallion Architecture, the Bronze layer often operates as a raw data lake — files arrive from source systems in their native format, with no transformation or schema enforcement. This raw landing zone preserves the original data exactly as received, enabling full reprocessing from source if needed. The table format layer begins at the Bronze-to-Silver transformation step.
Unstructured Data
Images, audio, video, PDFs, and other binary content do not fit naturally into a tabular format. These assets are stored as raw objects in the lake, with metadata (file location, content type, dimensions) tracked in a separate Iceberg table. Modern AI/ML pipelines increasingly process these assets directly via AI functions exposed by query engines like Dremio.
Data Science Experimentation
Data scientists often prefer direct file access for exploratory analysis — reading Parquet files with Pandas or PyArrow, writing custom transformations, and producing intermediate outputs without the overhead of creating formal Iceberg tables. The data lake's schema-on-read flexibility is ideal for this exploratory, iterative workflow.
Archive and Cold Storage
Historical data that is rarely queried — more than 3–5 years old — is often kept in raw file format in deep archive storage tiers (S3 Glacier, Azure Archive), without maintaining active Iceberg metadata. The cost savings are significant, and the data remains accessible when needed via one-time queries.
Transitioning from a Data Lake to a Data Lakehouse
Many organizations built data lakes between 2014 and 2022 and now face the question of how to transition to the lakehouse paradigm without rebuilding from scratch. The good news is that the migration is incremental — because both architectures use the same underlying cloud object storage and the same file formats (Parquet, ORC, Avro), the migration is primarily a metadata migration, not a data migration.
Step 1: Catalog Inventory
Audit your existing Hive Metastore or AWS Glue catalog. Identify tables that are actively queried, their current partition schemes, and their update/delete frequency. Tables with high update frequency or BI connectivity requirements are the highest priority for migration to Iceberg.
Step 2: Iceberg Table Migration
Apache Spark provides a migration tool (CALL system.migrate()) that converts existing Hive-partitioned Parquet tables to Iceberg format in-place, without copying data. The existing Parquet files become Iceberg data files, and new metadata files are written alongside them. After migration, the table appears as a native Iceberg table to all compatible engines.
Step 3: Catalog Migration
Replace the Hive Metastore with an Iceberg REST Catalog implementation — Apache Polaris, Project Nessie, or your cloud provider's native catalog. Configure all query engines to use the new catalog.
Step 4: Query Engine Upgrade
Introduce a high-performance query engine like Dremio to serve BI workloads. Configure Reflections on heavily queried Gold-layer tables for sub-second response times. Retire the previous Presto or Athena configurations for interactive queries.
Data Lake Security and Governance
One of the data lake's historically weakest dimensions was governance and security. Early data lakes had essentially no fine-grained access control — if you had access to the S3 bucket, you had access to all the data in it. This was a significant barrier to enterprise adoption, particularly for regulated industries.
Modern data lake security is enforced at multiple layers:
- Storage-layer ACLs: S3 bucket policies and IAM roles control which services and users can read or write which prefixes. This is coarse-grained and bucket-level.
- Catalog-layer access control: Apache Polaris, Nessie, and Unity Catalog enforce table-level, namespace-level, and privilege-level access control through the catalog API. Any engine connecting through the catalog inherits these controls.
- Engine-layer enforcement: Query engines like Dremio enforce role-based access control, column-level masking, and row-level filtering at query time, enabling fine-grained data security that the storage layer cannot provide.
- Data lineage and auditing: Tools like OpenMetadata and Apache Atlas track who accessed what data, when, and from which engine — providing the audit trail required for regulatory compliance.
The lakehouse architecture centralizes these controls through the catalog, making security enforcement consistent across all engines — a major advantage over the fragmented, engine-specific security model of the classic data lake.
Data Lake Tools and Ecosystem
The data lake ecosystem has matured substantially since the Hadoop era. Key tools in the modern data lake / lakehouse ecosystem include:
Ingestion
- Apache Kafka + Kafka Connect: Real-time event streaming and CDC from relational databases
- AWS Glue / Azure Data Factory / Google Dataflow: Managed ETL services for batch ingestion
- Airbyte, Fivetran: Connectors for SaaS source systems
Processing
- Apache Spark: The dominant large-scale batch and streaming processor for data lake transformations
- Apache Flink: Stream-first processing for real-time lakehouse pipelines
- dbt: SQL-based transformation framework increasingly used in lakehouses
Storage and Format
- Apache Parquet, ORC, Avro: The dominant file formats
- Apache Iceberg, Delta Lake, Apache Hudi: Table formats that transform a data lake into a lakehouse
Catalog and Governance
- Apache Polaris, Project Nessie, AWS Glue Catalog, Unity Catalog: Metadata and governance layers
Query and Analytics
- Dremio, Trino, Spark SQL, AWS Athena: Interactive and batch query engines
Summary: The Data Lake's Legacy
The data lake was a necessary and important architectural innovation. It democratized large-scale data storage, established the principle that compute and storage should be decoupled, and created the ecosystem of tools — Parquet, Spark, cloud object storage — that now underpins the modern data lakehouse.
Its failures — the data swamp problem, lack of ACID transactions, poor BI compatibility — were real and serious, but they were failures of the metadata layer, not of the underlying storage model. Apache Iceberg is the answer to those failures: it adds the transactional, governed metadata layer that the data lake was always missing, without abandoning the open storage model that made the data lake valuable in the first place.
Today, the term "data lake" is increasingly used to refer to the storage layer of a lakehouse — the object storage where raw and processed Iceberg files reside — rather than as a complete architecture in its own right. The data lake lives on as the foundation of the data lakehouse, contributing its best quality — cheap, open, scalable storage — while leaving its worst qualities — poor governance, no transactions, data swamps — behind.
For organizations still operating on a pure data lake without a table format, the path forward is clear: adopt Apache Iceberg incrementally, starting with your highest-priority analytical tables, and build the modern lakehouse on the storage foundation you already have.