What Is a Data Warehouse?
A data warehouse is a centralized analytical database designed to consolidate data from multiple operational source systems — ERP, CRM, transactional databases, SaaS applications — into a single, integrated, and historically consistent repository optimized for business intelligence and analytical reporting.
Unlike operational databases (OLTP systems) that are optimized for high-throughput, row-level reads and writes for transactional workloads, a data warehouse is designed for OLAP (Online Analytical Processing) — complex queries that aggregate, filter, and join large volumes of historical data across many dimensions. A typical OLAP query might sum all sales by product category and region for the past 36 months — a query that would overwhelm an OLTP database but that a well-designed data warehouse handles efficiently.
The concept of the data warehouse was formalized by IBM researchers Barry Devlin and Paul Murphy in 1988, and subsequently popularized by Bill Inmon (who defined it formally as a "subject-oriented, integrated, time-variant, and non-volatile" collection of data) and Ralph Kimball (who pioneered the dimensional modeling approach with star and snowflake schemas). By the late 1990s and early 2000s, on-premises warehouses from vendors like Teradata, Oracle, and IBM Netezza had become the backbone of enterprise analytics.
The transition to cloud-native warehouses in the 2010s — led by Amazon Redshift (2012), Google BigQuery (2011 public), and Snowflake (2014) — dramatically reduced the operational burden of running a data warehouse while improving performance and scalability. These platforms became the default analytical infrastructure for thousands of organizations.
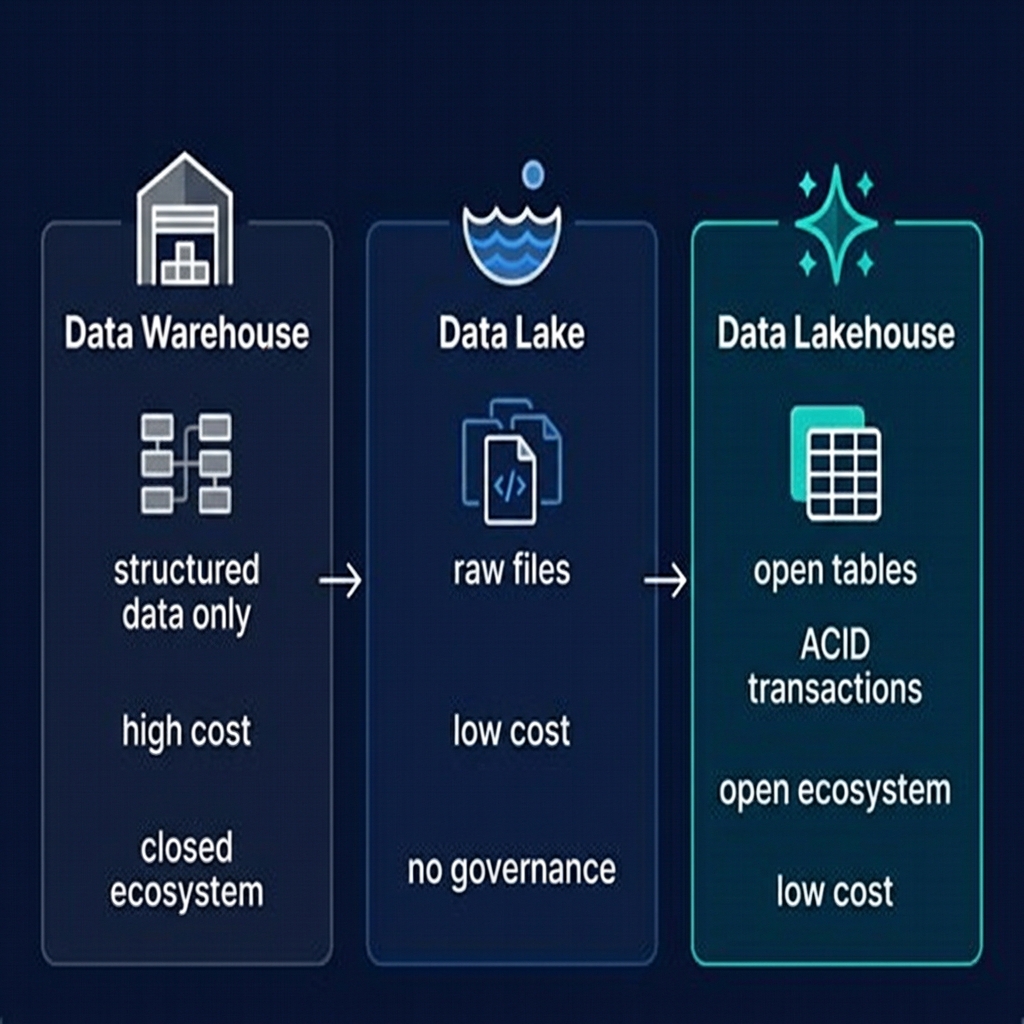
However, as data volumes grew into the petabyte range and organizations needed to support machine learning, streaming analytics, and increasingly open ecosystems, the fundamental architectural constraints of the proprietary data warehouse began to create friction. This friction is the primary driver of the data lakehouse movement.
How a Data Warehouse Works
A data warehouse operates on a distinct architectural pattern that separates source systems from the analytical layer through a multi-stage data pipeline.
The ETL Pipeline
Data enters the warehouse through an Extract, Transform, Load process. The Extract stage reads data from source systems — production databases, SaaS APIs, flat file exports. The Transform stage applies business rules: cleaning data, resolving entity identities, applying type conversions, aggregating records, and conforming dimensions across sources. The Load stage writes the transformed data into the warehouse's proprietary storage format.
ETL pipelines are expensive to build and maintain. A large enterprise might have hundreds of ETL jobs moving data from dozens of source systems, each requiring specialized engineering to handle schema changes, data quality issues, and pipeline failures. ETL teams — sometimes called data engineers — can become a bottleneck, slowing the time-to-insight for business stakeholders.
Storage Architecture
Modern cloud data warehouses use highly optimized columnar storage formats, stored in the vendor's proprietary format on the vendor's managed infrastructure. Columnar storage means that all values for a given column are stored together — ideal for analytical aggregations that touch many rows but few columns. This is why SELECT SUM(revenue) FROM orders WHERE year = 2025 is fast in a warehouse: only the revenue and year columns need to be read from storage.
Cloud warehouses like Snowflake have decoupled storage and compute — a significant architectural advance. Storage is separated from compute clusters (virtual warehouses in Snowflake terminology), meaning you pay for storage and compute independently and can scale each separately.
Query Processing
Warehouse query engines are massively parallel processing (MPP) systems that distribute query execution across many nodes. A complex aggregation query is broken into fragments, each fragment processes a partition of the data in parallel, and results are collected and merged by the coordinator node. MPP architecture delivers excellent performance on complex analytical queries — often sub-second for aggregations over hundreds of millions of rows.
Data Warehouse Schema Design: Star and Snowflake Schemas
The dominant schema design patterns in data warehouses are the star schema and snowflake schema, both developed by Ralph Kimball in the dimensional modeling tradition.
Star Schema
A star schema consists of a central fact table surrounded by dimension tables. The fact table contains the measurable events or transactions — sales orders, web sessions, sensor readings — with foreign keys to each dimension. Dimension tables contain descriptive attributes — customer names and demographics, product categories and descriptions, date hierarchies.
The star schema is called a star because its entity-relationship diagram resembles a star: fact table at the center, dimension tables radiating outward. It is optimized for query simplicity and performance — most analytical queries join a fact table to one or a few dimensions, which is efficient in columnar storage.
Snowflake Schema
A snowflake schema is a normalized extension of the star schema, where dimension tables are further broken down into sub-dimension tables. A product dimension might be broken into product, product_category, and product_subcategory. This reduces data redundancy at the cost of query complexity — more joins are required.
Modern Dimensional Modeling in the Lakehouse
In a data lakehouse, dimensional modeling still applies — it is a valid way to organize Gold layer tables for BI consumption. But the lakehouse also supports raw data in the Bronze and Silver layers, which don't follow a dimensional model. Dremio's Virtual Datasets and Reflections provide a way to define dimensional views on top of Iceberg tables without physically reorganizing the data.
The Limitations of the Data Warehouse
Despite its strengths, the data warehouse has fundamental architectural limitations that have driven organizations toward the data lakehouse:
Proprietary Lock-In
Data stored in a Snowflake warehouse is in Snowflake's proprietary format. Data stored in BigQuery is in BigQuery's proprietary format. Moving data out of these systems requires exporting to open formats — a process that can take hours or days for large datasets and costs significant compute and egress fees. This lock-in gives cloud warehouse vendors significant pricing power over their customers.
Cost at Scale
Cloud data warehouse storage costs are typically 5–15x higher per terabyte than cloud object storage. For organizations with petabyte-scale data requirements, this difference is material — often millions of dollars per year. The warehouse's high cost encourages organizations to be selective about what data they store, which in turn limits analytical flexibility.
Poor ML/AI Integration
Data scientists and ML engineers need access to raw data files — not SQL query results. Training a machine learning model on data stored in a cloud warehouse requires exporting it to object storage first, creating an expensive and time-consuming intermediate step. Warehouses were not designed for the iterative, exploratory workloads characteristic of ML development.
Single Engine Constraint
A data warehouse can only be queried by its own vendor's engine. You cannot run Apache Spark against Snowflake's internal storage, or use Trino directly against BigQuery's internal tables. This constraint means that organizations with multi-engine requirements — SQL analytics, ML training, stream processing — must maintain separate systems for each workload, duplicating data.
ETL Cost and Latency
The ETL process required to load data into a warehouse introduces latency — the gap between when an event occurs in a source system and when it is available for analysis. Traditional batch ETL runs nightly, meaning data can be 24 hours stale. Near-real-time ETL is possible but expensive to build and maintain. The ELT pattern — loading raw data first, transforming in the warehouse — reduces some latency but doesn't eliminate it.
Cloud Data Warehouses: Snowflake, BigQuery, Redshift, Synapse
The major cloud data warehouses each have distinct architectural characteristics and market positions:
| Platform | Cloud | Key Strength | Iceberg Support |
|---|---|---|---|
| Snowflake | Multi-cloud | Ease of use, multi-cloud portability | Yes (Iceberg tables) |
| Google BigQuery | GCP | Serverless, massive scale, ML integration | Yes (BigLake) |
| Amazon Redshift | AWS | AWS ecosystem integration | Yes (Redshift Spectrum) |
| Azure Synapse | Azure | Microsoft ecosystem, Power BI integration | Yes (Synapse Analytics) |
Notably, all major cloud data warehouses now support Apache Iceberg tables — a significant validation of Iceberg's role as the industry standard. This support allows organizations to query Iceberg tables stored in their own cloud object storage directly from the warehouse, without ingesting data into the proprietary format. This hybrid model reduces lock-in and enables multi-engine access.
However, native Iceberg query performance in cloud warehouses typically lags behind purpose-built lakehouse platforms like Dremio, which has deeply optimized its query engine for Iceberg's metadata model and can leverage features like Reflections that the cloud warehouses do not offer.
Data Warehouse Use Cases: Where They Still Win
Despite the rise of the lakehouse, cloud data warehouses remain the right choice for specific scenarios:
High-Concurrency BI Workloads
When hundreds or thousands of business users are running dashboards simultaneously against a relatively bounded, well-defined dataset, a cloud data warehouse's mature concurrency management and query result caching are hard to beat. Snowflake's multi-cluster architecture, for example, automatically spins up additional compute to serve concurrent load.
Modest Data Volume (Sub-10TB)
For organizations with data volumes under 10 terabytes, the engineering overhead of building and operating a lakehouse stack (Iceberg, catalog, multiple query engines, compaction jobs) may not be justified. A cloud data warehouse provides an operationally simpler solution at this scale.
Heavily Regulated, Structured Workloads
Financial reporting, regulatory compliance, and audit workloads often benefit from the warehouse's mature, proven governance capabilities — row-level security, column masking, fine-grained audit logging — that are built into the product rather than assembled from open-source components.
Existing Investment Protection
Organizations with large existing investments in warehouse schemas, ETL pipelines, and BI tool configurations may find incremental migration to a lakehouse more practical than a full replacement. Many choose a hybrid approach: keeping the warehouse for legacy workloads while building new projects on Iceberg.
Migrating from a Data Warehouse to a Lakehouse
The migration from a cloud data warehouse to a data lakehouse is one of the most common data engineering projects of the mid-2020s. The typical migration path follows these phases:
Phase 1: Export and Land in Object Storage
Export existing warehouse tables to Apache Parquet format in cloud object storage. Use the cloud provider's native export functionality (Snowflake COPY INTO, BigQuery export, Redshift UNLOAD) to minimize cost and complexity. Organize files following the target Medallion Architecture.
Phase 2: Create Iceberg Tables
Use Apache Spark or the Iceberg REST API to register the exported Parquet files as Apache Iceberg tables in your chosen catalog (Apache Polaris, Nessie, or cloud provider catalog). This step creates the Iceberg metadata layer on top of your existing files.
Phase 3: Connect Query Engine
Configure Dremio or another lakehouse query engine to connect to your Iceberg catalog. Define Virtual Datasets that replicate the logical schema of your warehouse tables, enabling BI tools to connect without changes.
Phase 4: Switch ETL Pipelines
Redirect ETL pipelines from writing to the warehouse to writing to Iceberg tables. Adopt an ELT pattern where possible — land raw data first, transform using dbt or Spark later.
Phase 5: Decommission the Warehouse
Once all workloads have been validated on the lakehouse, decommission the cloud warehouse subscription. The storage and compute cost savings typically justify the migration investment within 6–18 months.
Data Warehouse Governance and Security
One of the data warehouse's historically strong suits is governance and security. Cloud data warehouses provide mature, integrated capabilities:
- Row-Level Security: Policies that restrict which rows a user can see based on their role or identity — essential for multi-tenant analytics or regional data sovereignty requirements.
- Column-Level Masking: Dynamic data masking that replaces sensitive column values (SSNs, credit card numbers, email addresses) with masked representations for users without the appropriate privilege.
- Fine-Grained Audit Logging: Every query, login, and data access event is logged with user identity, timestamp, and query text — critical for compliance with SOX, HIPAA, GDPR, and similar regulations.
- Object Tagging and Classification: Data can be tagged with sensitivity labels (PII, Confidential, Public) and policies can be applied based on tags automatically.
The data lakehouse is rapidly catching up in governance capability. Apache Polaris and Unity Catalog provide table-level and column-level access control through the catalog. Dremio enforces role-based access control and column masking at the query engine level. OpenMetadata and Apache Atlas provide data lineage and tagging. The main difference is integration: warehouse governance is a single-vendor, integrated product; lakehouse governance is assembled from best-of-breed open-source components.
The Future of the Data Warehouse
The data warehouse is not disappearing — but it is evolving. The clearest signal of this evolution is the fact that every major cloud data warehouse now supports Apache Iceberg tables. Snowflake has Iceberg tables that store data in customer-owned S3 buckets. BigQuery supports reading Iceberg tables via BigLake. This is a fundamental architectural shift: the warehouse vendors are acknowledging that open storage is the future.
The likely future of the data warehouse is as a SQL compute engine that connects to open Iceberg storage, rather than as a vertically integrated storage+compute platform. In this future, organizations own their data in open format in their own cloud object storage, and they choose which compute engine to use for each workload: Dremio for interactive BI, Spark for batch ETL, Flink for streaming, and a cloud warehouse's SQL engine for specific high-concurrency use cases.
This future is the data lakehouse — where the warehouse provides one compute option among many, rather than a closed, vertically integrated stack. The shift is already underway, and the trajectory is clear.
Summary
The data warehouse was the defining analytical infrastructure of the enterprise for three decades. Its contributions — columnar storage, MPP query processing, dimensional modeling, governed BI — are foundational to the field of data engineering and directly inform the design of the modern data lakehouse.
Its limitations — proprietary lock-in, high storage cost, poor ML integration, single-engine constraint — created the conditions for the lakehouse revolution. Open table formats like Apache Iceberg, combined with open query engines like Dremio and open catalogs like Apache Polaris, deliver warehouse-grade performance and governance on open, low-cost cloud storage.
For data engineers and architects evaluating their data platform strategy in 2025 and beyond, the data warehouse remains a valid choice for specific, bounded workloads — but the data lakehouse is the more durable long-term architecture for organizations with diverse analytical needs, large data volumes, and a desire to avoid proprietary lock-in.