What Is Delta Lake?
Delta Lake is an open-source storage layer developed by Databricks that adds ACID transaction support, scalable metadata handling, and schema enforcement to Apache Spark workloads on cloud object storage. Released in 2019, Delta Lake was the first open table format to gain significant production adoption, pioneering many of the patterns — snapshot-based transactions, schema evolution, time travel — that are now standard across all open table formats.
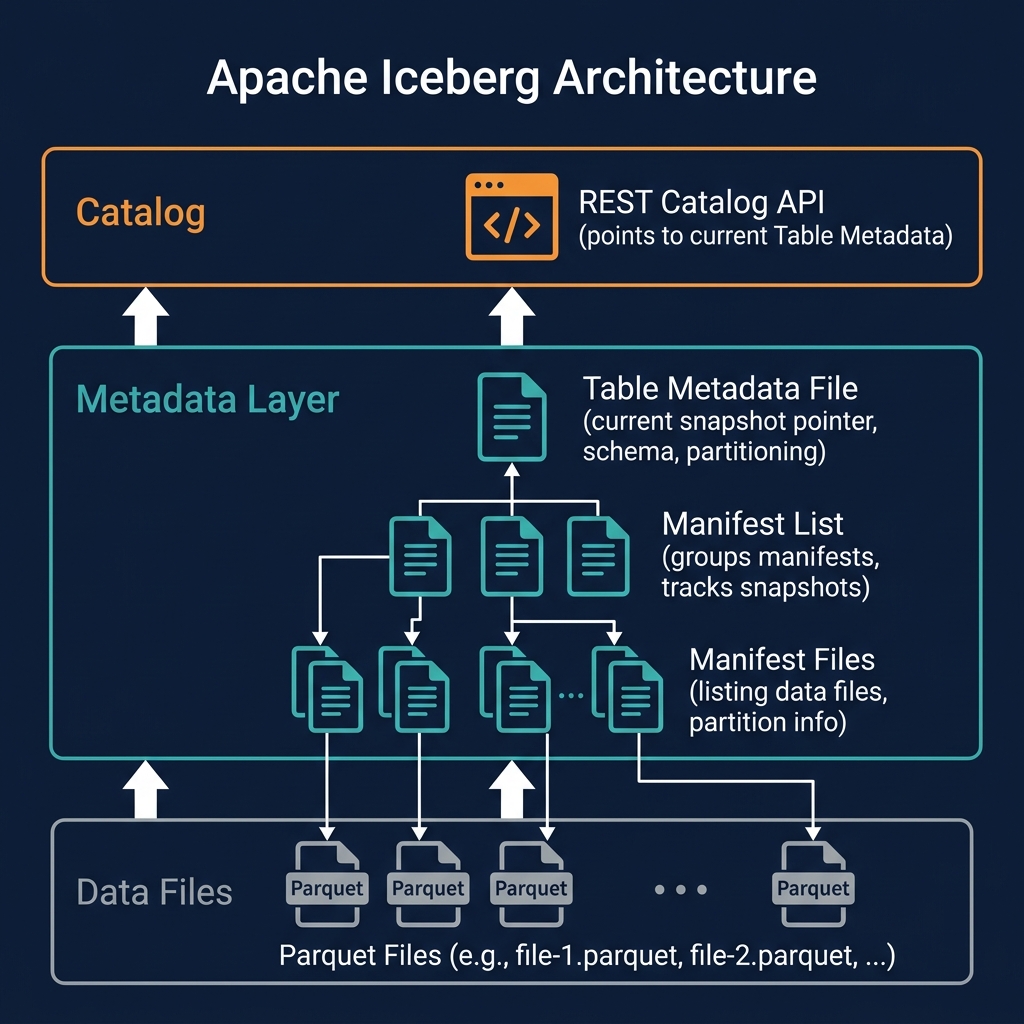
Delta Lake stores tabular data as Apache Parquet files in cloud object storage, exactly like Apache Iceberg and Apache Hudi. What distinguishes it is the transaction log mechanism: a folder named _delta_log within the table directory contains JSON commit files, one per transaction, that record every change made to the table. Periodically, the log is condensed into a Parquet checkpoint file for efficient log replay.
Delta Lake was donated to the Linux Foundation in 2023, transitioning from Databricks-controlled to community-governed open source. The core Delta Lake protocol is now documented as an open specification (Delta Protocol) that any engine can implement, and the Linux Foundation's governance ensures vendor neutrality.
In the 2025 landscape, Delta Lake is the dominant open table format within the Databricks ecosystem and has significant adoption among organizations that adopted Databricks as their primary data platform. Outside Databricks, Apache Iceberg has become the more widely supported format — particularly for multi-engine lakehouses and cloud-provider-neutral deployments.
How Delta Lake Works: The Transaction Log
Delta Lake's core mechanism is the Delta transaction log — a folder named _delta_log that lives alongside the Parquet data files in object storage. Understanding the log is the key to understanding how Delta Lake provides ACID guarantees.
JSON Commit Files
Every transaction committed to a Delta table produces a new JSON file in the _delta_log folder. Each JSON commit file records the actions of that transaction: which data files were added, which data files were removed, schema changes, metadata updates, and protocol changes. The commit file is numbered sequentially (00000000000000000001.json, 00000000000000000002.json, etc.), and the highest numbered commit file represents the current table state.
Parquet Checkpoints
As the transaction log grows (hundreds or thousands of commit files), replaying the entire log from the beginning to determine the current table state becomes expensive. Delta Lake addresses this with checkpoints: every 10 commits (by default), a Parquet checkpoint file is written that consolidates the entire current table state — all active data files, current schema, and current metadata — into a single file. Future log replays start from the most recent checkpoint rather than the beginning of the log.
ACID Atomicity in Delta Lake
Delta Lake achieves atomicity through the mutual exclusivity of commit file numbers. Two writers cannot both successfully write the same commit number — the object storage service's conditional write semantics (S3's conditional PUT, ADLS's conditional write) ensure that only one writer succeeds. The loser must read the new state and retry. This optimistic concurrency control provides serializable write semantics without a distributed lock manager.
Delta Lake Features
Delta Lake provides a comprehensive set of features that make it suitable for production analytical workloads:
ACID Transactions
Full ACID compliance with serializable isolation for writers and snapshot isolation for readers. Delta's transaction log ensures that readers always see a consistent state, even during concurrent writes.
Schema Enforcement and Evolution
Schema enforcement prevents data that doesn't match the table's schema from being written, catching data quality issues at ingestion. Schema evolution allows new columns to be added without rewriting data, and incompatible changes (column type narrowing) are rejected by default.
Scalable Metadata
Delta Lake's Parquet checkpoint mechanism addresses the metadata scalability problem that the Hive Metastore faced — even tables with billions of rows and millions of data files can be efficiently queried because the checkpoint consolidates all file metadata into a single Parquet file that can be read with column pruning.
Time Travel
Delta Lake supports time travel queries by version number or timestamp: SELECT * FROM table VERSION AS OF 5 or SELECT * FROM table TIMESTAMP AS OF '2026-01-01'. The transaction log's version history serves as the time travel index.
Liquid Clustering (2024)
A newer Delta Lake feature, Liquid Clustering optimizes data layout dynamically based on a set of clustering keys — similar to Iceberg's Z-ordering but with automatic, incremental optimization. It eliminates the need to choose static partition schemes upfront.
Delta Lake and the Databricks Ecosystem
Delta Lake's tightest integration is with the Databricks platform. Within Databricks, Delta Lake is the default table format, and Databricks provides several proprietary enhancements on top of the open-source core:
Delta Sharing
Delta Sharing is an open protocol for sharing data across organizations. A data provider exposes Delta tables through a sharing server; data recipients connect to the server and query the shared data using their preferred engine — without copying the data. Delta Sharing enables cross-organization data products and marketplace data monetization.
Unity Catalog
Unity Catalog is Databricks' unified governance layer for Delta tables (and, through UniForm, Iceberg tables). It provides table-level and column-level access control, data lineage tracking, and cross-workspace table sharing. Unity Catalog was open-sourced in 2024, joining Delta Lake as an open protocol.
Delta Live Tables
Delta Live Tables is Databricks' managed ETL framework that automatically manages data quality, incremental processing, and table optimization for Delta Lake pipelines. It implements the Medallion Architecture as a first-class concept within the Databricks UI.
Auto Optimize
Databricks automatically compacts small Delta files and optimizes file layout through background processes, similar to Dremio's automated table optimization for Iceberg. This reduces the operational burden of managing Delta table file health.
Delta Lake UniForm: Iceberg Compatibility Bridge
One of Delta Lake's most significant recent developments is UniForm (Universal Format) — a feature that automatically generates Apache Iceberg metadata alongside the Delta transaction log, making Delta tables simultaneously readable by Iceberg-compatible query engines.
With UniForm enabled on a Delta table, any Iceberg-compatible engine — Dremio, Trino, Apache Spark with Iceberg — can read the table using Iceberg's REST catalog interface, without knowing that the underlying format is Delta. Writers continue to commit using Delta's transaction log protocol; a background process generates the equivalent Iceberg metadata after each commit.
UniForm is Databricks' pragmatic response to Apache Iceberg's emergence as the catalog interoperability standard. Rather than forcing Iceberg-first engines to implement Delta compatibility, UniForm allows Delta tables to participate in the Iceberg ecosystem without a full format migration. This is a meaningful capability for organizations that are primarily on Databricks but need to share data with teams or tools that are Iceberg-native.
The limitation of UniForm is that it is a bridge, not native parity: the generated Iceberg metadata lags the Delta log by a background job latency, and some Delta-specific features (Delta Sharing, Delta constraints) do not have Iceberg equivalents. For organizations whose primary ecosystem is Iceberg-native, using Delta tables with UniForm adds operational complexity without the benefits of native Iceberg.
Delta Lake vs. Apache Iceberg: When to Choose Which
The choice between Delta Lake and Apache Iceberg is primarily organizational, not technical:
| Scenario | Recommendation | Reason |
|---|---|---|
| Primary platform is Databricks | Delta Lake | Native integration, Delta Live Tables, Unity Catalog |
| Multi-engine lakehouse (Spark + Dremio + Trino) | Apache Iceberg | Native support in all engines without UniForm bridge |
| Cloud-native AWS (no Databricks) | Apache Iceberg | Native S3 Tables, Athena, Glue support |
| Migrating from Databricks to multi-engine | Apache Iceberg | Delta UniForm as a bridge during migration |
| Need Dremio as query engine | Apache Iceberg | Dremio's deepest native format support |
| Data sharing across orgs | Delta Lake (Delta Sharing) | Delta Sharing protocol is mature and widely supported |
In 2025, most new greenfield lakehouses default to Apache Iceberg. Delta Lake migration to Iceberg is feasible using Spark's CONVERT TO ICEBERG procedure (for CoW tables) or by registering Delta table files directly as Iceberg tables. Organizations already deeply invested in Databricks and Delta Lake can use UniForm to gain Iceberg compatibility without a full migration.
Delta Lake Performance
Delta Lake performance is optimized primarily for the Apache Spark execution model, with several features designed to maximize Spark query efficiency:
Data Skipping with Delta Statistics
Delta Lake collects column-level min/max statistics during writes (for the first 32 columns by default). At query time, the Databricks optimizer uses these statistics to skip data files that cannot contain matching rows. On well-organized data, this can reduce the files read by 80–90%.
Z-Ordering
Delta Lake's OPTIMIZE ZORDER BY command co-locates rows with similar values in the same data files, maximizing the effectiveness of data skipping for multi-column filter predicates. This is particularly effective for exploratory workloads with diverse filter patterns.
Liquid Clustering
The newer replacement for static Z-ordering, Liquid Clustering incrementally optimizes data layout without requiring full table rewrites. It is more efficient for continuously updated tables where Z-ordering's full rewrites are prohibitively expensive.
Photon Engine
Databricks' proprietary Photon execution engine, optimized for Delta Lake, provides vectorized, C++-implemented query execution that significantly outperforms standard Spark for analytical queries. Photon is a Databricks-proprietary capability not available on open-source Spark.
Migrating from Delta Lake to Apache Iceberg
As Apache Iceberg has become the industry standard, many organizations are evaluating or executing migrations from Delta Lake to Iceberg. The migration path depends on the workload:
In-Place Migration (Copy-on-Write Tables)
For Delta tables using Copy-on-Write semantics only, Apache Spark provides the CONVERT TO ICEBERG procedure that creates an Iceberg table by registering the existing Parquet files as Iceberg data files and generating new Iceberg metadata. No data is copied — this is a metadata-only migration that completes in minutes even for large tables.
Rewrite Migration (Merge-on-Read Tables)
Tables with Delta delete files (using Merge-on-Read semantics) require a full rewrite to Iceberg format, since Iceberg's delete file format differs from Delta's. This is typically done by reading the Delta table with Spark and writing the result as a new Iceberg table using INSERT INTO iceberg_table SELECT * FROM delta_table.
Parallel Migration with UniForm
Enable UniForm on existing Delta tables to make them immediately Iceberg-readable, then gradually migrate consumers to use the Iceberg interface. Once all consumers are on Iceberg, decommission the Delta table and create a native Iceberg table as the final step.
Delta Lake Governance and the Linux Foundation
The 2023 donation of Delta Lake to the Linux Foundation marked a significant shift in governance. Under the Linux Foundation, the Delta Lake project is governed by a Technical Steering Committee with representation from Databricks, Microsoft, Nvidia, and other organizations. The Delta Lake protocol is now a community standard rather than a Databricks product.
However, the Linux Foundation's governance model differs from the Apache Software Foundation's in important ways. The ASF has stronger vendor-neutrality traditions and a longer track record of successfully managing contentious, multi-stakeholder open-source projects. Databricks, despite no longer being the sole controller, remains by far the largest contributor and most influential voice in Delta Lake development.
For enterprise organizations, this governance distinction matters for long-term risk assessment. Apache Iceberg's ASF governance provides stronger assurance that no single vendor can steer the format's direction in ways that serve vendor interests over user interests. This is a key reason why cloud providers and infrastructure vendors have coalesced around Iceberg rather than Delta Lake as the common denominator format.
Summary
Delta Lake pioneered open table format technology — it was the first to prove that ACID transactions, schema enforcement, and time travel were practical on cloud object storage at scale. Its contributions to the data engineering field are significant, and it remains the most mature and feature-rich option for Databricks-centric organizations.
In the broader market, Apache Iceberg has emerged as the more widely supported standard — particularly for multi-engine lakehouses, cloud-neutral deployments, and organizations using Dremio as their primary query engine. The Iceberg REST Catalog specification, ASF governance, and native support from every major cloud provider give Iceberg a structural advantage as the common denominator for the lakehouse ecosystem.
For organizations evaluating their table format strategy in 2025, the pragmatic guidance is: use Delta Lake if you are on Databricks; use Apache Iceberg for everything else. UniForm provides a compatibility bridge if you need to transition gradually.