What Is an Open Table Format?
An open table format is a metadata specification that adds a structured, transactional layer on top of raw data files stored in cloud object storage. Without an open table format, data in a data lake is just a collection of files — Parquet, CSV, or JSON objects arranged in folders. These files have no concept of a schema, no transaction history, no way to safely update or delete individual records, and no mechanism for multiple engines to access them concurrently without risk of corruption.
An open table format solves all of these problems. It maintains a metadata layer — separate from the actual data files — that tracks the table's schema, partitioning structure, file inventory, transaction history, and statistics. Query engines read this metadata to understand what data exists and where, then access only the relevant data files. Writers use the metadata layer to implement atomic commits — ensuring that readers always see a consistent, fully committed state.
The word "open" in open table format is critical. These specifications are open standards — publicly documented, freely implementable, and not controlled by any single vendor. This openness is what enables multi-engine interoperability: Apache Spark, Trino, Dremio, Apache Flink, and cloud services all implement the same specification, meaning they can all read and write the same tables without coordination from a central authority.
The three open table formats in mainstream use today are Apache Iceberg, Delta Lake, and Apache Hudi. Each was developed independently to solve the same fundamental problem — adding database-like semantics to data lake storage — but they differ in their design philosophy, feature set, governance model, and ecosystem support. As of 2025, Apache Iceberg has emerged as the clear industry standard.
Why Open Table Formats Exist: The Problem They Solve
To understand why open table formats exist, consider what happens to a data lake without one:
No Atomic Writes
When a Spark job writes a new partition to S3, it writes multiple files sequentially. If the job fails halfway through, partially written partitions appear in the folder — containing some rows but not others. Readers that query during the write see incomplete data. Without a transaction log, there is no way to know which files are fully committed and which are partial.
No Safe Concurrent Access
Two Spark jobs writing to the same partition simultaneously will overwrite each other's output files, producing data loss. Without a concurrency control mechanism, data lakes must be written serially — a significant operational constraint for large organizations with many data producers.
No Native Updates or Deletes
Object storage does not support in-place file modification. To update a single row in a Hive-partitioned Parquet table, you must read the entire partition, modify the row in memory, and rewrite all the partition's files. For large tables with frequent updates — or for GDPR data deletion requirements — this is prohibitively expensive.
No Schema Evolution
Hive Metastore's schema model is limited — adding columns requires table-level DDL that may invalidate existing files or require rewriting them. Renaming columns requires a complete table rebuild. These constraints severely limit a data team's ability to evolve data models over time without downtime.
No Performance Metadata
Without file-level statistics (min/max values per column, null counts, row counts), query engines must scan every file in a partition to evaluate filter predicates. For large tables, this results in massive unnecessary I/O.
Open table formats solve all of these problems by adding a structured, transactional metadata layer between the raw files and the query engines.
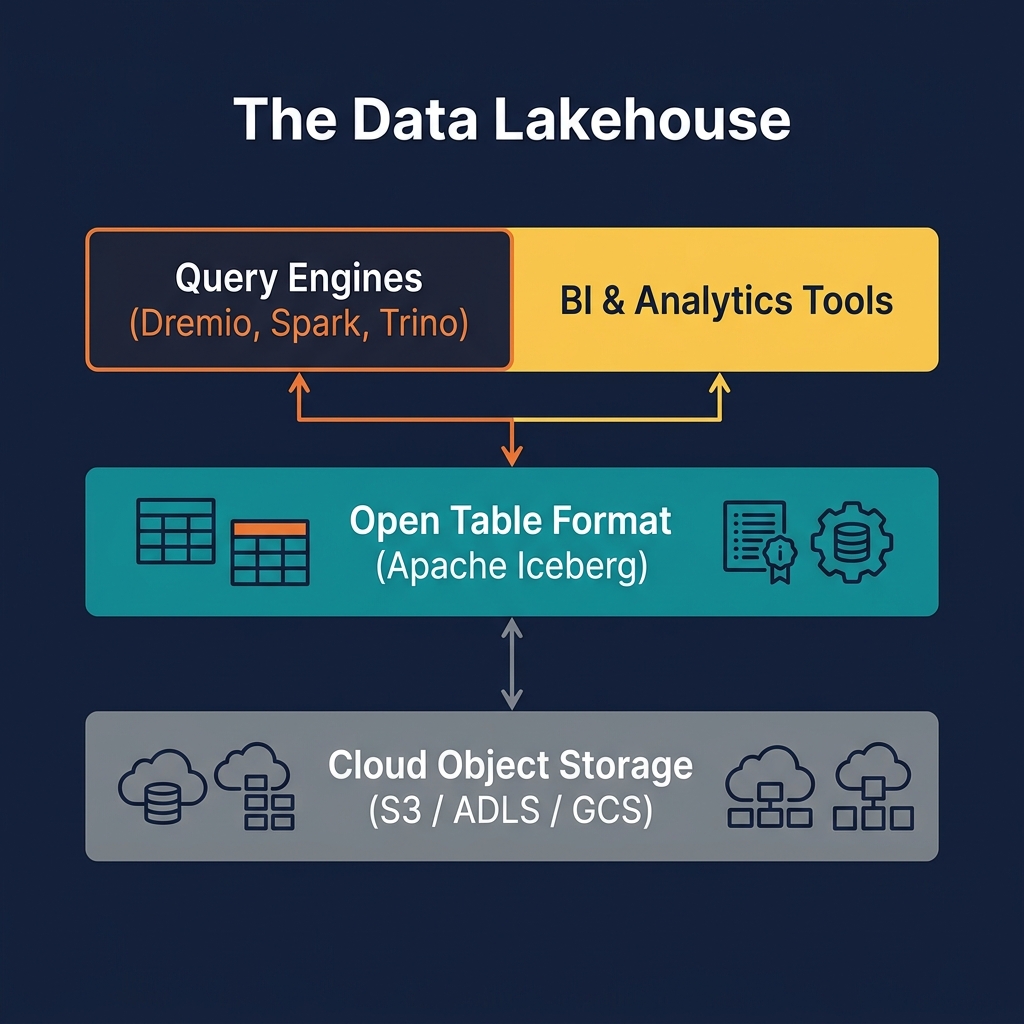
How an Open Table Format Works
All three major open table formats — Iceberg, Delta Lake, and Hudi — share a common architectural pattern: a metadata tree that organizes data files and tracks their history.
Data Files
At the base are the actual data files — typically Apache Parquet files containing the table's rows in columnar format. These files are immutable: once written, they are never modified. New data is written to new files; deleted or updated rows cause the original files to be replaced by new files (in Copy-on-Write mode) or supplemented by delete files (in Merge-on-Read mode).
Metadata Files
Above the data files is a metadata layer that tracks their structure. In Apache Iceberg, this consists of manifest files (listing the data files in a snapshot, with per-file statistics), manifest lists (grouping manifest files into a snapshot), and a table metadata file (recording the current snapshot, schema, partition spec, and sort order). Each committed transaction creates a new set of metadata files and atomically swaps the pointer to the current metadata file.
Transaction Log
The metadata layer serves as the table's transaction log. Because each write creates a new metadata snapshot, the history of all writes is preserved indefinitely (until explicitly expunged by a cleanup operation). This history enables time travel — queries can reference any historical snapshot by timestamp or snapshot ID.
Catalog Pointer
The Iceberg REST Catalog (or Hive Metastore, or Delta Log's checkpoint) maintains a single authoritative pointer to the table's current metadata file. When a writer commits a transaction, it atomically updates this pointer. When a reader queries the table, it follows this pointer to find the current snapshot. This atomic pointer swap is the mechanism that provides serializable transaction semantics.
Apache Iceberg: The Industry Standard
Apache Iceberg is the open table format that has emerged as the industry standard as of 2024–2025. Originally developed by Netflix and Apple and donated to the Apache Software Foundation in 2018, Iceberg was designed from the ground up for massive scale — tables with billions of rows and millions of data files — and for true multi-engine interoperability.
Key Iceberg Capabilities
- Schema evolution: Add, drop, rename, reorder, and change column types without rewriting data files
- Partition evolution: Change partitioning schemes over time without rewriting historical data
- Hidden partitioning: Partitioning is transparent to query writers — no need to filter on partition columns explicitly
- Time travel: Query any historical snapshot by timestamp or snapshot ID
- Row-level deletes: Positional and equality delete files for efficient row-level operations without full partition rewrites
- File-level statistics: Per-column min/max values, null counts, and row counts enable aggressive data skipping
Iceberg Governance
Iceberg is governed by the Apache Software Foundation, the gold standard for open-source governance. The specification is publicly documented and freely implementable. No single vendor controls the roadmap. This governance model is a key reason Iceberg has attracted broad industry support — from AWS, Azure, Google, Snowflake, Databricks, Dremio, and hundreds of other organizations.
The Iceberg REST Catalog Specification
Beyond the table format itself, the Iceberg project has defined an Iceberg REST Catalog specification — a standard HTTP API for catalog operations (table creation, metadata lookup, namespace management). This specification enables true multi-engine, multi-catalog interoperability: any engine that implements the REST Catalog client can connect to any catalog that implements the REST Catalog server, without any engine-specific configuration.
Delta Lake: The Databricks Format
Delta Lake was developed by Databricks and open-sourced in 2019. It is the native table format for the Databricks platform and has significant adoption among organizations using Databricks for their lakehouse. Delta Lake stores its transaction log in a _delta_log folder within the table directory, consisting of JSON commit files and periodic checkpoint files in Parquet format.
Delta Lake Strengths
- Deep integration with Databricks and Apache Spark — Delta Lake operations are optimized for Spark execution
- Delta Sharing — a protocol for sharing Delta tables across organizations and query engines without copying data
- Liquid Clustering (2024) — an alternative to traditional partitioning that clusters data based on column values, similar to Iceberg's Z-ordering
- Universal Format (UniForm) — a Delta Lake extension that generates Iceberg metadata alongside Delta Log metadata, making Delta tables readable by Iceberg-compatible engines
Delta Lake Limitations
Delta Lake's governance was historically controlled by Databricks. In 2023, it was donated to the Linux Foundation, which improved its openness. However, it lacks the Apache Software Foundation's decades of neutral governance precedent. Its catalog interoperability story (via UniForm) is a bridge rather than native Iceberg support. Organizations not using Databricks as their primary compute platform typically find Apache Iceberg a more natural choice.
Apache Hudi: The Streaming-Optimized Format
Apache Hudi (Hadoop Upserts Deletes and Incrementals) was developed by Uber and donated to the Apache Software Foundation in 2019. Hudi was designed with a specific use case in mind: efficient upsert and delete operations for large-scale streaming CDC (Change Data Capture) workloads where individual records must be updated or deleted frequently.
Hudi Strengths
- Efficient upserts: Hudi's index mechanism (Bloom filter, HBase-based, or record-level) makes finding and updating specific records fast — particularly valuable for CDC workloads
- Incremental processing: Hudi provides native incremental pull APIs, making it easy to build pipelines that process only changed data
- Two table types: Copy-on-Write (CoW) for read-optimized workloads, Merge-on-Read (MoR) for write-optimized workloads
- Streaming-first: Deep integration with Apache Flink and Spark Streaming
Hudi Limitations
Hudi has significantly narrower query engine support than Apache Iceberg. Its catalog story is less developed, and its specification is less commonly implemented by non-Hudi tools. For organizations whose primary driver is streaming CDC, Hudi remains a strong choice. For general-purpose lakehouse use, Apache Iceberg is typically preferable.
Choosing an Open Table Format
For organizations starting a new data lakehouse in 2025, the decision matrix is relatively straightforward:
| Factor | Apache Iceberg | Delta Lake | Apache Hudi |
|---|---|---|---|
| Primary engine | Any (Dremio, Spark, Trino, Flink) | Databricks / Spark | Spark / Flink |
| Governance | Apache Software Foundation | Linux Foundation | Apache Software Foundation |
| Cloud warehouse support | All major warehouses | Partial (via UniForm) | Limited |
| Best for | General-purpose lakehouse | Databricks-centric orgs | High-frequency CDC upserts |
| Catalog standard | Iceberg REST Catalog | Unity Catalog / HMS | Hive Metastore |
| Row-level operations | Excellent (V2 delete files) | Good | Excellent (Hudi specialty) |
Recommendation for 2025: Default to Apache Iceberg. Its governance model, ecosystem breadth, and catalog interoperability standard make it the most durable long-term choice. If your organization is deeply committed to Databricks, Delta Lake with UniForm gives you Iceberg compatibility as a bridge. If your primary workload is high-frequency streaming CDC, evaluate Hudi seriously — but be aware of its narrower ecosystem.
Open Table Formats and the Dremio Platform
Dremio is one of the deepest implementers of the Apache Iceberg specification, treating it as the native storage model for the entire platform rather than as one of many supported formats.
Dremio's Iceberg integration includes:
- Full DML support: INSERT, UPDATE, DELETE, and MERGE INTO operations against Iceberg tables using ANSI SQL syntax
- Metadata-driven optimization: Dremio's query planner reads Iceberg's per-file min/max statistics to prune irrelevant files before any data is read from object storage
- Automated table optimization: Dremio automatically compacts small files, clusters data for common query patterns, and vacuums expired snapshots on Iceberg tables without manual intervention
- Reflections on Iceberg tables: Dremio can build transparent materialized views (Reflections) on any Iceberg table, providing sub-second query acceleration for BI workloads
- Open Catalog: Dremio's Open Catalog implements the Iceberg REST Catalog specification, allowing any Iceberg-compatible engine — not just Dremio — to catalog and access tables
This deep Iceberg integration means that organizations running Dremio are not locked into Dremio's query engine — their data is in standard Iceberg format, accessible by any compliant engine. This is the embodiment of the open table format principle: open storage that any engine can use.
The Future of Open Table Formats
The open table format space is evolving rapidly, driven by growing adoption and increasing enterprise requirements:
Iceberg V3
The Apache Iceberg community is developing V3 of the specification, which will add support for variant data types (for semi-structured JSON/Avro data within Iceberg tables), improved deletion file compaction, and enhanced support for real-time streaming scenarios.
Universal Format Convergence
Delta Lake's UniForm and Hudi's Hudi Catalog Service both aim to make their respective formats compatible with Iceberg-compatible engines. This convergence is driven by the recognition that Iceberg's REST Catalog specification has become the de facto standard for catalog interoperability — even competing formats are aligning to it.
AI-Native Table Features
As AI and agentic workloads grow, open table formats are being extended with features relevant to AI — variant columns for storing embedding vectors, metadata hooks for MLflow experiment tracking, and integration with the Model Context Protocol for AI agent data access.
Real-Time Convergence
The boundary between streaming and batch is blurring. Future versions of Apache Iceberg will provide native support for streaming write protocols, eliminating the need for Hudi's specialized streaming features and making Iceberg a single format for both batch and real-time workloads.
Summary
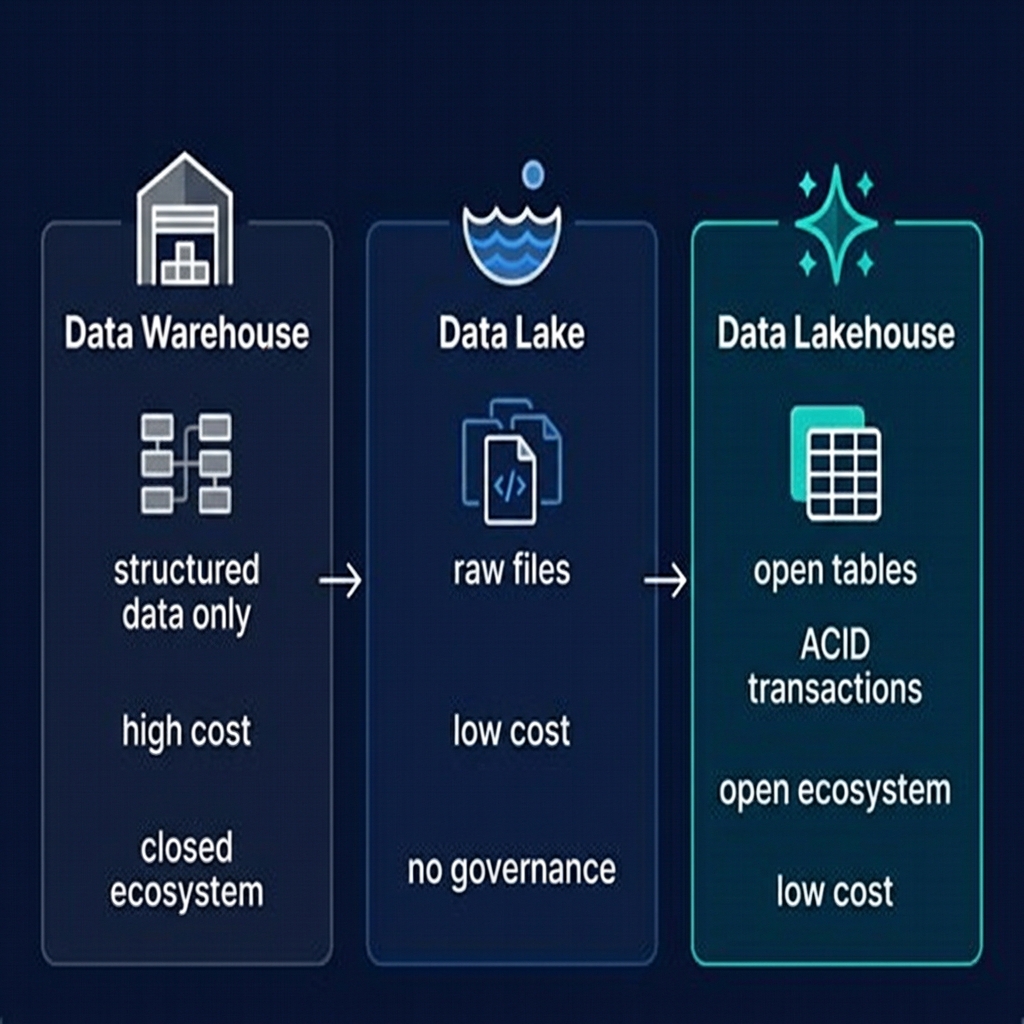
The open table format is the technology that makes the data lakehouse possible. By adding a transactional, schema-aware metadata layer on top of raw data files in object storage, open table formats transform a disorganized data lake into a governed, high-performance analytical platform that supports ACID transactions, time travel, schema evolution, and multi-engine interoperability.
Among the three major open table formats — Apache Iceberg, Delta Lake, and Apache Hudi — Apache Iceberg has emerged as the industry standard, with the broadest ecosystem support, the most vendor-neutral governance, and the most complete specification. For any organization building a new data lakehouse in 2025, Apache Iceberg is the default choice.
Platforms like Dremio have built comprehensive lakehouse products on the foundation of Apache Iceberg, demonstrating that an open, vendor-neutral table format is fully capable of delivering enterprise-grade performance and governance without proprietary lock-in.