What Is a Data Lakehouse?
The data lakehouse is a modern data management architecture that merges two previously distinct paradigms — the data lake and the data warehouse — into a single, unified platform. Rather than maintaining separate systems for raw data storage and governed analytics, the data lakehouse treats your cloud object storage layer as the single source of truth, and applies a structured open table format on top of it to deliver warehouse-grade capabilities.
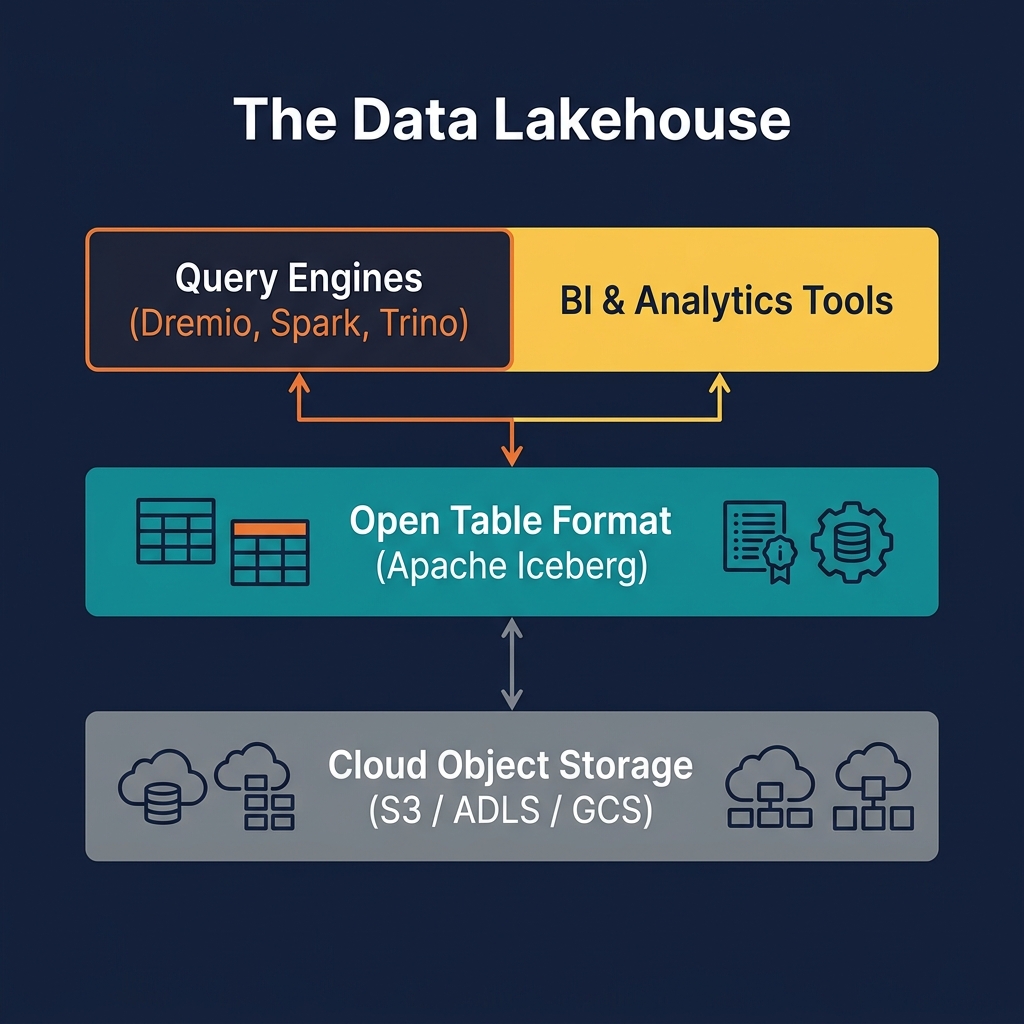
At its core, a data lakehouse consists of three layers. The storage layer is commodity cloud object storage — Amazon S3, Azure Data Lake Storage (ADLS), or Google Cloud Storage (GCS). Raw data files, typically in Apache Parquet or ORC format, live here. The table format layer — most commonly Apache Iceberg — provides the metadata and transactional machinery that organizes those files into logical tables with schemas, partitions, snapshots, and transaction logs. Finally, the compute layer consists of one or more query engines — such as Dremio, Apache Spark, Trino, or Apache Flink — that read and write through the table format layer.
The term was coined and popularized by Databricks and subsequently defined academically in a 2021 paper by researchers at UC Berkeley RISE Lab. Since then it has become the dominant paradigm for enterprise data architecture, displacing the traditional cloud data warehouse as the default starting point for net-new analytics systems.
The key insight of the lakehouse architecture is that open file formats on cloud storage are now fast enough, and open table formats provide enough structure, that there is no longer a compelling reason to copy your data into a proprietary warehouse system. You pay less, maintain more flexibility, and avoid vendor lock-in — all while getting the reliability and performance you expect from a warehouse.
The lakehouse concept also reflects the recognition that data should be stored once and queried many times, by many different engines for different purposes — SQL analytics, machine learning, streaming, and increasingly, agentic AI workloads. A traditional warehouse cannot serve all these use cases. An unstructured data lake cannot serve them reliably. The lakehouse can.
Why the Data Lakehouse Matters
To understand why the data lakehouse matters, it helps to understand what came before it — and where both approaches failed.
The data warehouse was the dominant analytics system for three decades. It offered excellent SQL performance, strong consistency guarantees, and a structured schema model that business analysts loved. But it came with serious limitations: data had to be copied and transformed into the warehouse's proprietary format, which was expensive both in storage cost and ETL engineering time. Warehouses were closed systems — you could only use the vendor's query engine, at the vendor's price. And they were poorly suited to machine learning workloads, which needed raw access to the underlying data files.
The data lake was the answer to the warehouse's cost and flexibility problems. By storing raw data in open formats on cheap cloud object storage, organizations could ingest data from any source without pre-defining schemas, and data scientists could access raw files directly with Spark or Python. But data lakes quickly became swamps: without a transactional layer, concurrent writes corrupted data, deletes and updates were nearly impossible, data quality deteriorated, and BI tools couldn't connect reliably.
The data lakehouse resolves this tension. ACID transaction support from Apache Iceberg means concurrent readers and writers operate safely. Schema enforcement prevents data quality issues. Time travel enables point-in-time queries and data auditing. And because everything is stored in open files on commodity storage, costs are dramatically lower than a proprietary warehouse — often by a factor of 5–10x at scale.
Perhaps most importantly, the lakehouse supports a multi-engine ecosystem. The same Apache Iceberg table can be read by Dremio for interactive SQL, by Spark for batch ETL, by Flink for streaming, and by Python notebooks for machine learning. No data copying required. This is the defining architectural advantage of the lakehouse.
In 2024 and 2025, the industry reached a clear consensus: Apache Iceberg is the standard table format for the lakehouse, with native support from every major cloud provider (AWS, Azure, Google Cloud), every major query engine, and every major orchestration and catalog tool.
How a Data Lakehouse Works: The Technical Architecture
Understanding how a data lakehouse works requires understanding its three architectural layers in detail.
Layer 1: Cloud Object Storage
All data in a lakehouse lives in cloud object storage as files. These files are immutable — once written, they are never modified in place. This immutability is fundamental to the lakehouse's transaction model. The most common file format is Apache Parquet, a columnar format that supports efficient predicate pushdown and column pruning. Apache ORC and Apache Avro are also used, with Avro most common for schema-registry use cases.
Layer 2: The Open Table Format
Apache Iceberg sits between the raw files and the query engines. It maintains a metadata tree — a snapshot log that records every transaction, manifest lists that index every data file, and manifest files that track file-level statistics. When a query engine wants to read a table, it reads the metadata to determine exactly which files are needed, pruning irrelevant ones using partition information and column statistics. When a writer commits a new transaction, it creates new metadata files atomically, guaranteeing that readers always see a consistent snapshot.
This architecture enables snapshots for time travel, schema evolution without rewrites, partition evolution without full table scans, and true ACID semantics even across multiple concurrent writers.
Layer 3: The Compute / Query Engine
Query engines connect to the lakehouse through an Iceberg REST Catalog or a native catalog integration (like Apache Polaris or Project Nessie). The catalog tells the engine where to find each table's current metadata. The engine then reads the metadata, plans an optimized query, and fetches only the necessary data files from object storage — often achieving dramatic performance through predicate pushdown and column pruning.
Dremio takes this further with Reflections — materialized, pre-aggregated or pre-projected views of Iceberg data that transparently accelerate queries without requiring users to change their SQL. This is how the lakehouse achieves sub-second query performance on petabyte-scale datasets.
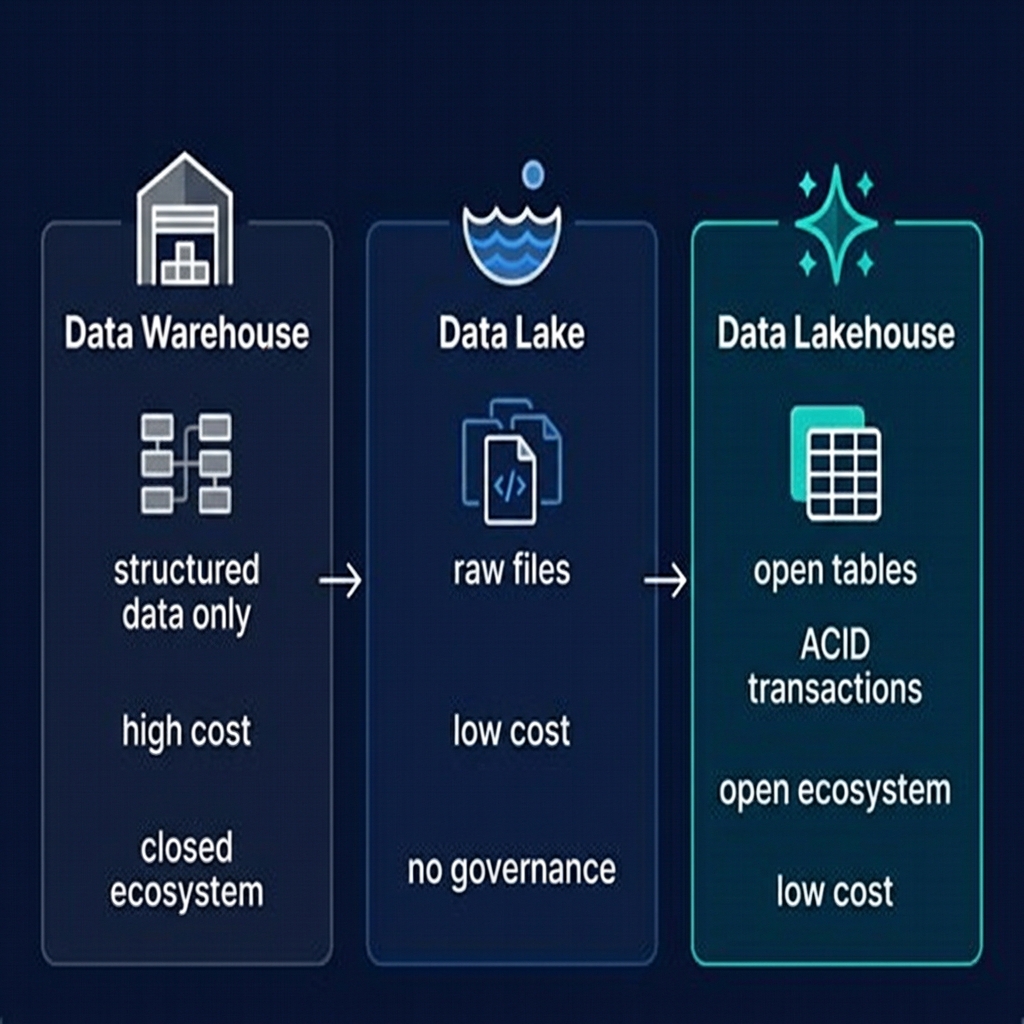
Data Lakehouse vs. Data Warehouse vs. Data Lake
The simplest way to understand the lakehouse is through direct comparison with the two architectures it supersedes.
| Dimension | Data Warehouse | Data Lake | Data Lakehouse |
|---|---|---|---|
| Storage format | Proprietary, closed | Open files (Parquet, CSV) | Open files + table format (Iceberg) |
| ACID transactions | Yes | No | Yes |
| Schema enforcement | Strict (schema-on-write) | None (schema-on-read) | Enforced via table format |
| Storage cost | High (proprietary) | Low (object storage) | Low (object storage) |
| Query engines | Single vendor engine | Any engine | Any engine (multi-engine) |
| ML / AI workloads | Difficult | Native | Native |
| Time travel | Limited / expensive | No | Yes (via snapshots) |
| BI performance | Excellent | Poor without tuning | Excellent (with Reflections) |
| Vendor lock-in | High | Low | Low |
| Data freshness | Batch ETL lag | Near real-time possible | Near real-time via streaming |
The lakehouse does not merely split the difference between warehouse and lake — it supersedes both. For new analytics systems started in 2024 or later, there is almost no scenario where a traditional cloud data warehouse is the better architectural choice.
The Medallion Architecture: Organizing Data in the Lakehouse
Most lakehouse implementations organize data into the Medallion Architecture — a layered data quality model with three tiers: Bronze, Silver, and Gold.
Bronze is the raw ingestion layer. Data arrives here from source systems — databases, APIs, event streams — with no transformation. Bronze tables are append-only and serve as the historical record. They are typically partitioned by ingestion date.
Silver is the cleansed, conformed layer. Bronze data is validated, deduplicated, standardized, and joined across sources. Silver tables represent a single version of truth for each business entity — a clean customer table, a unified order table. They use Iceberg's Merge-on-Read or Copy-on-Write strategies to support efficient upserts and deletes.
Gold is the business-ready layer: dimensional models, aggregations, and domain-specific views that BI tools and dashboards query directly. Gold tables are heavily optimized — compacted, Z-ordered, and often accelerated by Dremio Reflections for sub-second query latency.
This three-layer pattern is powerful because it separates concerns: ingestion logic lives in the Bronze-to-Silver pipeline, business logic lives in the Silver-to-Gold pipeline, and serving logic lives at the Gold layer. Each layer can evolve independently, and the immutability of underlying Iceberg snapshots means you can always reprocess from raw data if a business rule changes.
Multi-Engine Interoperability: The Lakehouse's Superpower
The single most underrated feature of the data lakehouse is multi-engine interoperability. Because all data is stored in open Apache Iceberg tables, any compliant engine can read and write the same data without copying it.
In a typical enterprise lakehouse, this means:
- Apache Spark runs nightly batch ETL jobs that transform Bronze tables into Silver
- Apache Flink streams CDC events from production databases into Bronze tables in near-real-time
- dbt defines Gold layer transformations as SQL models, executed on schedule
- Dremio serves interactive SQL queries and BI tool connections against Gold and Silver tables with sub-second latency via Reflections
- Python notebooks connect directly to Iceberg tables via the PyIceberg library for exploratory data science and ML feature engineering
All of these engines operate on the same tables, in the same storage, simultaneously — without coordination overhead or data copying. This is only possible because Apache Iceberg's snapshot isolation model guarantees that each reader sees a consistent view of the data regardless of what writers are doing concurrently.
This multi-engine reality also protects organizations from vendor lock-in. If you decide to switch your primary query engine from Trino to Dremio — or add Flink for streaming — your data needs no migration. The Iceberg tables remain unchanged. Only the compute layer changes.
The Role of Catalogs and Governance in the Lakehouse
A data lakehouse without a catalog is like a library without a card catalog: the books exist, but nobody can find them reliably. The catalog is the service that tracks the location, schema, and current metadata pointer for every Iceberg table in the lakehouse.
Modern lakehouses use the Iceberg REST Catalog specification — an open HTTP API that any catalog implementation can satisfy and any query engine can connect to. This means you can swap catalog backends without changing your query engine configuration.
The most important catalog implementations in 2025–2026 are:
- Apache Polaris — donated to the Apache Software Foundation by Snowflake; now the community standard for open, vendor-neutral Iceberg catalog management
- Project Nessie — the catalog behind Dremio's lakehouse offering, notable for its Git-like branching and tagging semantics for data versioning
- AWS Glue Data Catalog — Amazon's managed catalog with native Iceberg support
- Unity Catalog — Databricks' unified governance catalog, now open-sourced
Beyond table discovery, enterprise lakehouses also require governance: data lineage tracking, role-based access control, column-level security, and data quality monitoring. Tools like OpenMetadata, Apache Atlas, and Apache Ranger integrate with the lakehouse to provide these capabilities on top of the underlying Iceberg tables.
Dremio provides native governance capabilities through its Open Catalog offering, which combines catalog management with access control, lineage, and the ability to define a curated semantic layer through Virtual Datasets.
Data Lakehouse with Dremio
Dremio is purpose-built for the data lakehouse. Where some query engines treat Iceberg as one of many supported formats, Dremio treats Apache Iceberg as its native storage model — and builds a comprehensive lakehouse platform on top of it.
The key Dremio capabilities relevant to the lakehouse are:
Intelligent Query Engine
Dremio's query engine is built on Apache Arrow for vectorized in-memory processing. It performs aggressive predicate pushdown into Iceberg's metadata layer, skipping irrelevant files before they are even accessed from object storage. For repeated analytical queries, Reflections provide transparent materialized acceleration — the query optimizer automatically routes queries to the most efficient pre-computed representation of the data.
Open Catalog
Dremio's Open Catalog, powered by Apache Polaris, provides a governed, multi-engine catalog for Iceberg tables. It exposes the standard Iceberg REST Catalog API, meaning any Iceberg-compatible engine can connect to it — not just Dremio.
Semantic Layer
Through Virtual Datasets, Dremio lets data teams define a business-friendly semantic layer on top of raw Iceberg tables. These virtual datasets behave like SQL views but with additional capabilities: they can be accelerated with Reflections, versioned, and exposed to BI tools via standard ODBC/JDBC or Arrow Flight connections.
Automated Table Optimization
Dremio automatically compacts small files, optimizes sort orders, and vacuums expired snapshots on Iceberg tables — without requiring manual DBA intervention. This keeps query performance high as data accumulates over time.
Common Lakehouse Implementation Challenges
Building a data lakehouse is significantly simpler than it was in 2020, but several common challenges remain:
Small File Problem
Streaming ingestion and frequent small transactions create many small Parquet files, which degrades query performance. The solution is regular compaction — merging small files into optimally sized ones. Dremio automates this; in other systems it requires scheduled Spark or Iceberg maintenance jobs.
Catalog Sprawl
Organizations often end up with multiple catalogs (one per engine, one per cloud region, one per business unit), fragmenting the metadata layer and defeating governance objectives. The Iceberg REST Catalog standard and tools like Apache Polaris and Project Nessie help centralize catalog management.
Schema Management at Scale
As data sources evolve, schemas change. Iceberg's schema evolution handles most changes gracefully, but organizational discipline is still required: data producers need to follow a change management process so that downstream consumers are not broken.
Partition Strategy
Poorly chosen partition strategies result in data skew and slow queries. Iceberg's hidden partitioning helps by abstracting partitioning from query writers — queries automatically benefit from partition pruning without the user knowing the partition layout. However, the underlying partition choice still matters enormously for performance.
Access Control Complexity
Securing data at scale — column-level masking, row-level filtering, cross-engine policy enforcement — requires careful integration between the catalog, the query engine, and governance tools. Dremio and Apache Ranger provide complementary approaches to this problem.
Best Practices for Data Lakehouse Architecture
Based on production deployments at scale, the following best practices have emerged for data lakehouse architecture:
- Adopt Apache Iceberg from day one. All three major open table formats (Iceberg, Delta Lake, Hudi) work, but Iceberg has the broadest ecosystem support in 2025–2026. Starting with Iceberg avoids future migration costs.
- Use the Medallion Architecture consistently. Bronze/Silver/Gold is not just a naming convention — it encodes important data quality and access control boundaries. Gold tables should never be written directly from external sources.
- Centralize your catalog. Pick one catalog (Polaris, Nessie, or Glue depending on your cloud) and route all engines through it. Catalog fragmentation is a governance and operability anti-pattern.
- Automate compaction and maintenance. Never let small file accumulation go unchecked. If your query engine does not automate this (Dremio does), schedule maintenance jobs in Spark or the Iceberg REST API.
- Define a semantic layer early. Before BI tools connect directly to raw Iceberg tables, define a curated set of Virtual Datasets or views that encode business logic. This prevents each analyst from independently re-implementing the same joins and business rules — and makes future schema changes manageable.
- Monitor data quality continuously. Integrate a data observability tool (Great Expectations, Monte Carlo, or Dremio's native profiling) to catch schema drift, null rate changes, and volume anomalies as early as possible.
- Plan for the Agentic AI workload. AI agents increasingly query lakehouse data directly via MCP (Model Context Protocol) servers or SQL interfaces. Design your semantic layer with machine-readable descriptions and ensure your access control model can safely scope agent permissions.
The data lakehouse is not a product — it is an architectural pattern that requires disciplined implementation. Organizations that invest in the right foundations early will have a durable, scalable analytics platform that can adapt to new compute engines, new AI workloads, and new data sources without expensive migrations.
Summary and Next Steps
The data lakehouse represents the most significant architectural shift in enterprise data management in a generation. By combining the low cost and openness of a data lake with the reliability and performance of a data warehouse — through the mechanism of open table formats like Apache Iceberg — it eliminates the false choice organizations previously faced between flexibility and governance.
Key takeaways from this guide:
- A data lakehouse stores data in open files on cloud object storage, structured by an open table format (Apache Iceberg) that provides ACID transactions, schema evolution, time travel, and multi-engine interoperability.
- The Medallion Architecture (Bronze/Silver/Gold) is the standard organizational pattern for lakehouse data layers.
- Catalogs like Apache Polaris and Project Nessie manage metadata and governance across all engines.
- Dremio provides a purpose-built lakehouse platform with an intelligent query engine, open catalog, semantic layer, and automated table optimization.
- The Agentic Lakehouse is the next frontier — AI agents querying and reasoning over lakehouse data in real time.
To go deeper, explore the related concepts below, or pick up one of the recommended books to take your lakehouse knowledge to the next level.